3 ( From: https://blog.lunaixsky.com/article/37 )
5 > 我们将会在这一章节里面深入探讨LunaixOS的虚拟文件系统的设计思路,以及一些实现上的细节。文章将会从文件系统的基本概念出发,解释我们为什么需要虚拟文件系统这一抽象层的存在,以及我们应该如何如设计这一抽象层。我们会涵盖文件系统中的每个概念,这包括:文件的打开,读写,软硬链接,页缓存实现的IO提速,缓存管理,挂载点管理;以及文件系统与多进程模型的整合,这将会包括:文件系统在并发环境下的同步机制,文件描述符与进程的整合。篇幅较长,大约三万字,涉及的概念较广,还请各位耐心阅读。
7 终于,我们来到了这一步——文件系统。这其实是一个相当奇怪且矛盾的话题,这话怎么说呢,文件系统之概念在操作系统理论教科书上的是相当的简单易懂,符合直觉。可是你若说他简单,当你开始着手用代码将他实现出来的时候,会教你一遍遍质疑自己的编程能力。诚然,这也怪不得多少自制OS在这里被下了降头,又有多少OS因为这个而被迫产出“屎山”一般的代码。当然,这话其实还是有点主观,毕竟文件系统的实现也可以是简单的:随便找个现有的文件系统,比如ISO9660,照着他的标准直接按部就班的写就行了。但是这样产生的代码的耦合度会相当的高,那么自然地,日后的拓展和维护将会是你的噩梦。那么假若你想要做好,实现一个通用的,灵活的文件系统——一个抽象层,一个所有文件系统的“大统一理论”,或者也叫做 **虚拟文件系统(Virtual File System, VFS)** ,那就是颇具挑战性了,正如同前面我说的那些吓人的话一样。
9 也正因为文件系统这一特点,LunaixOS在实现这文件系统这一功能的过程中可谓是一路坎坷,不过好在还是摸到了门路,最终的成果也算是相当的令人满意,功能非常的齐全,所提供的文件系统相关的系统调用几乎覆盖POSIX标准和一部分Linux的特性,这前前后后总共花费了笔者一个多月的时间。那么在这篇文章中,我将会与大家分享LunaixOS的虚拟文件系统的设计思路和实现细节,同时也会探讨一些开发过程中遇到的问题和解决方案。
13 这个问题的答案在上述的开篇中已经被简短的提到过了,无非就是我们希望有一个“大统一理论”,一个抽象层去方便我们日后的维护和拓展,这也是软件工程理论中所提倡的。但是我希望对这个简短的答案进行进一步的拓展。这主要就是因为有太多太多的操作系统教程(不论是书籍还是网络的视频教程),都没有涵盖虚拟文件系统的重要性和具体设计,而只是随便找个文件系统(意料之中的,几乎都是选用最简单的FAT32)进行编写实现,然后紧紧的将内核中的其他的子系统与之耦合起来,最后产生了一个极难维护的,“Demo”水平的,屎山。当然了,我能够想到此时有读者或许不赞同我的观点:教学第一,那么一切都要从简,所以这些操作系统教程这么安排是相当的合情合理的。是的,的确是这样的。可是我还是决定从虚拟文件系统开始入手,为大家提供另一个视角。
15 当然,在开始之前,让我们以一个相当老套的问题来作为引子:“什么是文件系统?” Well,是个人都知道,文件系统就是用来管理文件的。双击某个文件夹,打开一个窗口,里面鳞比栉次排列着你辛苦收集的各种“教学视频”——这些都是文件系统最直观的体验。而这也就是大部分普通人对此的理解。
17 但是我们可不是普通人,我们是要开发操作系统的,是老练的内核开发者!那么在我们的眼中,文件系统也就褪去了那层肤浅的外表,而将他的本质暴露了出来:文件系统是一个规定数据应当在存储介质中如何进行存取的协议。那么按照这个类比继续思考,我们就不难发现,所谓“实现一个文件系统”其实就相当于实现一个“驱动程序”,一个文件系统协议的驱动程序。
19 
21 如同上图所示,存储介质驱动(Medium Driver)从位于硬件层的存储介质(Storage Medium)读出数据,其产生的原生数据流(Raw Data Stream)将发送给上层的文件系统驱动(Filesystem Driver),后者将这些数据流翻译成具有着某些结构的,人类能够理解的东西——也就是我们熟知的文件,文件夹了。
23 那么这大概就是文件系统的定义了,那么从这个定义出发,我们能够更好的去分析一个文件系统需要具备的功能和元素,从而帮助我们进行最终的实现。
27 不知道各位是否曾想过,在计算机被发明出来的这七十多年的时间里,究竟诞生过多少个文件系统?肯定不止NTFS和FAT32!那么有多少呢?我不知道确切的数目,但我可以很自信的告诉你,是有上百个的!我可不是在夸张,Wikipedia上面可是有[专门的一页](https://en.wikipedia.org/wiki/List_of_file_systems)用来列举。很意外的吧!但也不要觉得不知所措。别看这些五花八门的文件系统,他们之间的区别其实都是“大同小异”的:大同于文件系统之目的——管理和组织在磁盘上文件;小异于文件系统之专精:他们也许是突破了现有的某个文件系统一些局限性,而后自成一派——比如ext系列和NTFS系列,他们分别是对最早的minixfs和fat32进行的一个全面提升;也许是针对某些应用场景进行了一些优化,比如exFAT就是针对便携式闪存设备的优化。也许是一些性能上的提升……等等诸如此类。这些所有的不同之处,其实都可以被用我们上图所展示模型去归类。
32 有很多例子,比如说单个文件最大大小,单个目录下最多包含的文件数……等等在软件上的限制都可以作为日后其他文件系统的突破口。像ext2就是一个非常好的例子,它是对minix文件系统的一个改进,包括但不限于:拓展了文件名长度(原有的14字符到255字符),拓展了分区大小,单个文件大小。
35 这主要就是一些拓展功能,比如文件的自定义属性(xattr);允许对全文件系统执行用户透明的解压缩操作(如NTFS)。
38 一些文件系统允许**文件系统层面的加密(Filesystem-level Encryption)**。这不同于文件内容的加解密,因为后者仅仅只是加密了内容,而文件系统的一些元数据,比如说文件目录的拓扑结构,或者是文件自身的元数据,依然是以明文形式存放在硬盘上的。所以,这一类密码学文件系统就是用来解决这一痛点的。比较具有代表性的就是eCryptFS,NTFS的EFS功能,以及ext4。
41 计算机不是稳定,特别是那些长期运行的。服务器崩溃再上线,搞运维的此时心中唯一的祈祷就是数据都还在,并且完整。这主要是因为文件的操作并非是我们想象的原子操作。举个简单的例子,文件的写入可以拆成三个步骤:1、在磁盘上分配空间(如有需要);2、写入数据;3、更新文件的元数据;假若在这三个动作之间存在中断——比如设备崩溃时,数据写入了,但元数据没有更新;或者是磁盘空间分配了,但没有写入。这种就是中间状态(Intermediate State),也是文件损毁的一个象征。所以,一个文件系统对于这种严重的外部中断的容错率,也就决定了这份祈祷究竟灵不灵验。也因为这一点,人们后来就开发出了**日志文件系统(Journaling file system)**,正如其名,这类文件系统会记录整个操作的步骤,以及所期望的状态,以便中断发生后能够正常的恢复。比较知名的文件系统有:NTFS,ext3,ext4。
44 正如同程序一样,一个文件系统有他的时间复杂度和空间复杂度。如时间复杂度:在目录下查找某个文件的速度,从磁盘读取文件内容的速度——这类的性能的提升往往需要考虑到存储媒介的物理特征;那么空间复杂度也就显而易见了,即对存储介质的空间利用率。
48 在一般情况下,文件系统所面向的存储介质无非就是安装在本地上的一块儿硬盘,那么这么一来,这种存储驱动就无非是,AHCI,NVMe的,或是什么其他存储技术的HBA,等等——类似这种对本地存储设备直接操控的文件系统我们叫做 **磁盘文件系统(Disk Filesystem, DiskFS)** 。也有一些情况,比如说是 **网络文件系统(Network Filesystem, NFS)** ,这种文件系统所面向的介质可能位于某个服务器上,而此时存储驱动很可能就是只是一个TCP/IP协议栈。哪能不能两者共存呢?当然可以,比如 **分布式文件系统(Distributed Filesystem, DFS)** ——这其实是网络文件系统的一个特例。像这类文件系统他所管理的数据是遍布整个网络的。那些什么什么云盘网盘就是一个很好的例子,一个文件有可能是被拆成好几块,东一块西一块的,分布在不同服务器上的磁盘里。那么当用户请求下载一个文件的时候,可能某个服务器会做出响应,然后尝试从本地的存储中进行查找,假若只有部分块存在,那么那些不存在的块的信息就会被转发至别的服务器进行尝试。类似的文件系统有GFS(Google Filesystem)和OrangeFS。
49 
53 不同的文件系统会对不同的存储设备有着不同的优化,比如光驱设备——这种存储媒介上的数据基本上在刻录的一瞬间就确定是不会发生变动了。那么也自然就不需要在文件系统自带修改或扩充文件的功能了——文件系统的设计就可以得到极大地简化,和在效率上的提升。这也就是为什么,我们会有ISO9660这么一个单独的,专门给光驱设计的文件系统。类似的例子还有很多,比如前文提到的exFAT是对于闪存设备专门优化的FAT类型文件系统,以及为SSD设计的TrueFFS。
55 对于上述所提到的文件系统,由于他们都是对实际存放在某个地方的数据进行操控的,所以我们在这里都统称为 **物理文件系统 (Physical Filsystem)**。与之相反的——当然不是虚拟文件系统——是 **伪文件系统 (Pseudo Filesystem)** ,这一类文件系统所操作的数据并非是常驻于现实世界中的某个地方,而是位于内存中,是被操作系统内核动态的创建出来的。其存在的目的可能有很多,不过最常见的是三点:
57 + 用于内核态暴露,比如Linux下的`sysfs`,`procfs`。
58 + 简化对设备访问,以及对其的映射,如LunaixOS中的`devfs`,Linux下的`udev`。
59 + 用于对现有文件系统进行进一步的抽象,如Linux下的`overlayfs`。对于这个用例,一个常见的场景便是Ubuntu发行版(当然也包括其他的发行版)的LiveCD模式。它允许用户在正式安装系统前试用系统。在这个试用的过程中,系统自身是运行在用ISO9660文件系统格式化的媒介上(也就是制作启动盘的iso文件)。从原则上,这个文件系统是只读的。那么为了带给用户完全的试用体验,我们就需要对ISO9660进行进一步的抽象,将创建文件,写入,等等其他非只读的操作旁路到别的什么地方(比如内存)。
61 这两种文件系统,因为他们不论如何都是直接与底层的数据流打交道的,我们就将他们称之为 **实际文件系统 (Concrete Filesystem, CFS)**。相对的,就是我们的念念不忘的 **虚拟文件系统** 了。这三者之间的关系我们可以用下图进行简单的概括。
63 
65 可以看到,在这世界上确实有着如此多的文件系统等着我们去支持!假若一锤定音的写死一个文件系统,那的确是有点太冒险了。为了日后的维护性和拓展性,我们需要一个抽象层来统一所有的文件系统。
67 
69 根据我们上面归类的几个文件系统之间的不同点,我们很容易看到,一个文件系统的抽象层必须要具备的四个责任:
73 3. **消除不同实际文件系统之间的边界**
76 第三、第四点我们将会在后面的小结中逐个探讨。那么在目前,就让着重去讨论前两个责任应该去如何保证。我之所以选择这两个方面开始探讨,并不是因为他的序号;而是责任一、二的落实,是同我们的虚拟文件系统的架构设计有着相当密切的关系。
80 不同的文件系统,也许对文件在存储介质中的组织有着不同的规定。但不论如何,所有的这些在底层的不同,都是可以被抽象成简单的文件-目录表示方法。在进行深入的讨论之前,我们来对这两者下个简单的定义:
82 + 文件是一堆有着特定目的的二进制数据的组合体。
85 根据上述的两条定义,我们可以引申出下面的推论:
89 3. 结合上述第二点推论:任何文件的位置都可以通过将文件名按照层级顺序进行组合来表示。
91 那么这五点的定义与推论也就构成了我们现在最常见的多级文件组织方法,目录与目录之间相互嵌套,形成一种树形结构。在这种组织方法内的文件都可以通过“路径”这一概念(推论三)来定位。
93 同时,这种多级文件组织的方法,除了能够为用户带来更加符合直觉的,高效的,文件管理体验。也能够为用户的赋予极大地灵活性和可拓展性。一个非常显然的例子就是我们挂载点的概念(我们将在之后的章节进行深入的讨论)。这种功能允许用户将位于不同物理介质中的不同的文件系统,都纳入一个统一的文件树下进行管理和访问。而这也就蕴含了我们责任一以及责任三。出于这一点的原因,我们的虚拟文件系统将采用这种多级文件组织方式,来进行文件表达方式上的统一。
97 <summary>对推论一的证明</summary>
99 我知道读者或许对我如此较真的行为感到非常的奇怪,特别是对这种常识性的东西。虽然我知道这的确是有点多此一举,但是我希望能够通过这一点,让大家看到,万物后面都是有着一些理性和逻辑存在的。同时这也算是我们正式化(formalising)整个文件系统之概念的第一步。
101 要证明这一推论其实相当的简单。首先,让我们来回忆一下计算理论中的知识点。令语言 $\mathcal{L}_d$ 为所有可能的“目录”实例的集合;语言 $\mathcal{L}_f$ 为所有可能的“文件”实例的集合。那么,证明“目录本身是一个文件”,就相当于证明语言 $\mathcal{L}_d$ 和语言 $\mathcal{L}_f$ 之间存在一个映射归约(mapping reduction),即 $\mathcal{L}_d \leq_m \mathcal{L}_f$ 。那么我们唯一的任务就是证明存在一个可计算的编码方式 $c$,使得 $c(\mathcal{L}_d) \subseteq \mathcal{L}_f$。
103 现在我们开始证明:令字符集 $\Sigma=\{0,1\}$,根据文件的定义,我们可以知道 $\mathcal{L}_f=\Sigma^*$。 根据目录的定义,我们有 $\mathcal{L}_d=\mathcal{L}_f^*$。那么对于任意的一个目录 $d=\{f_1,f_2,\dots\}\in\mathcal{L}_d$,其中 $f_i\in\mathcal{L}_f$,我们定义出一个编码函数 $c:\mathcal{L}_d\mapsto\Sigma^*$,
106 c(d) = \sigma(f_1)f_1\sigma(f_2)f_2 \cdots
109 其中 $\sigma:\mathcal{L}_f\mapsto\Sigma^*$,为大小函数,其目的就是统计输入的0或1的数量,然后将结果编码为固定长度的二进制输出。显然,根据Church–Turing论题(Church–Turing Thesis),这种函数是可计算的(Computable);换言之,会存在一个图灵机 $\mathcal{M}_\sigma$(或程序)去计算它的。然后我们可以按照同样的方法,去证明$c$的可计算性:
111 + 对于输入的 $d$ 中的每个 $f_i$ 进行以下步骤:
112 1. 将 $f_i$ 作为 $\mathcal{M}_\sigma$ 的输入,并运行。
116 于是我们也就证明了编码函数 $c$ 的可计算性。由于 $\mathcal{L}_f=\Sigma^*$, 所以 $c:\mathcal{L}_d\mapsto\Sigma^*\Rightarrow c:\mathcal{L}_d\mapsto\mathcal{L}_f$。那么这也就是说明,总会有一种可计算的编码方式,使得 $c(\mathcal{L}_d) \subseteq \mathcal{L}_f$。
124 那除了这种多级的表达方式外,还有别的表达方式吗?当然有,这种多级组织方法其实是存在一种目前并不多见的特例,即单级组织方法。即所有的文件都位于一个单独的目录下——或者说是,没有目录这一个概念。采用这种的文件系统大部分已经被历史的车轮给轧没了,比如早期的MS-DOS采用的FAT8文件系统,和世界上第一台超级计算机,CDC 6600。
126 当然了,我所说的是“大部分”,及至目前为止,仍然有少部分的应用场景是采用这种组织方式的——比如在一些类似于嵌入式设备这种低性能的平台上;或者是追求高性能的,而且对文件管理没有特别要求的监控系统。这主要是因为效率的缘故。要看到这一点,假设我们需要从文件系统中定位一个文件。对于单级组织的来说,他所做的唯一的一个事情就是去遍历存储在磁盘中的文件记录表,最终找到的文件就是我们想要的。那么在这种情况中,由于文件记录表是连续的,所以空间局部性得到了很好的利用。而对于多级存储来说,由于层级的存在,从文件记录表中寻找到的有可能是指向另一个记录表的指针(或者说是目录文件)——如果运气好的话,这可能是位于下一个扇区;当然,这也有可能是位于几百个扇区之后!但从一般情况来看,这种行为势必会造成地址空间上的不连续,从而需要存储介质驱动进行重新寻址,造成极差的空间局部性。我们都知道,硬盘是位于“内存金字塔”中的第四层,所以,在这种地方的空间局部性的利用率会极大地影响到总体的性能。
128 还有一种相当新奇,但颇受部分人欢迎的组织方式。这也就是标签化管理。这种管理方式最广为人知的应用场景就是在苹果公司推出的MacOS操作系统上。在这个系统里,文件管理器允许用户为不同的文件或目录打上不同的颜色作为标签。比如红色可以标记一些紧急代办事项,蓝色可以标记一些已经归档的文件——这将极大地提升用户的生产力。
130 不过标签化组织方式他并非是某种文件系统独有的,所以也自然不会自称一派。事实上,标签化管理在很多情况下,是与我们上述讨论的两种组织方案共存的。而且也是可以从用户空间去实现的。因为从本质上,标签是用户赋予文件的一个自定义属性,所以,一个可能的实现就是利用相关的系统调用,如Linux下的`getxattr`和`setxattr`。那么,假若一个文件系统支持**拓展属性(Extended Attribute)**,如ext系列,和NTFS,那么这种标签化组织方案就可以得到应用。
132 可是尽管如此,这种从用户空间上实现的标签化管理还是有些性能上的问题。当用户想查看某个标签下的所有文件时,那么他们就必须得要枚举出所有的文件,并进行一个聚合和过滤。这样子会给底层IO和缓存层带来极大地压力。所以,最好的方案还是需要提供文件系统层面的原生支持。不过,俗话说的好:办法总比困难多——我们依然可以在用户空间里实现标签化管理。我们采用的另一种方式就是一种被称之为 **动态目录映射 (Dynamic Directory Mapping)** 的方法。其原理很简单,一个文件的路径里所包含的所有目录名称,都视作位与这个文件相关联的标签。
134 我们可以举个简单的例子,比如一首来自电视剧 *My Little Pony: Friendship is Magic* 第`i`季,第`j`集的歌曲`k.mp3`。那么其标签可以就是:`music`, `mlp-fim`, `s_i`, `ep_j`。按照上述的映射方法,那么这个文件的路径应该为:`music/mlp-fim/s_i/ep_j/k.mp3`。这里唯一的难点就是在于如使得文件的路径独立于标签的顺序——不管我们怎么排列标签的顺序,我们都必须保证最后得到的是同样的路径;以及去动态的管理目录结构。一些文件系统,像[TagFS](http://www.xam.de/2006/01-tagfs.pdf),和[dhtfs](https://code.google.com/archive/p/dhtfs/),就是采用这类方式实现标签化的。可以看到,这种方式还是需要以我们最常见的树形组织方式的文件系统作为底层。所以,标签文件系统依然是作为用户层面上对内核层的虚拟文件系统的一个抽象去实现的。对于这类文件系统我们可以统称为**用户层文件系统(Filesystem in USErspace, FUSE)**。
136 那么话又说回来,一个纯粹的标签化文件系统究竟可不可行?——这里的纯粹指的是一种完完全全独立于层级式文件组织方案的一种实现。也就是说,没有目录和路径的概念。答案是可行的(理论上,因为我没有找到现实生活中的例子)。但是没有必要,原因有三点:
140 计算机已经诞生了七十多年,而作为诞辰之初就出现的目录-文件形式表示方式,也已经是成了全世界人民某种心照不宣的默契和行业标准。在这种大环境下,实现这种纯粹标签化文件系统,就显得有些画蛇添足,多此一举了。更何况,当这种文件系统被集成进现有的操作系统的虚拟文件子系统中,依然会退化为目录-文件形式。非常的划不来。
143 一个程序的运行可能需要他的数据文件,就比如你平日下载的游戏,和所用的软件。程序的本体已不再是单个的可执行文件那么简单了,而是有着大量高度结构化的数据文件,库文件,作为支撑。那么,假若一个程序被安装在电脑上,那么他就必须要将用来定位数据文件的标签注入到系统全局的“标签池”中,从而污染了系统的标签空间。那么这么一来,用户定义的标签或许就会淹没在一大堆乱七八糟的自动生成的标签里面——这可谓是适得其反,因为整个标签化文件系统的用处就是为了最大化用户的生产力。
146 每个标签都是自成一派的,都是独立于别的标签的存在。这种特性也就导致了其弱上下文环境的问题。那么这就很有可能会出现文件,或标签同名称冲突的情况——这种情况在层级化组织中不会出现,因为目录层级的存在,是相当于自动做了一个上下文环境隔离。
148 种种原因,在内核虚拟文件系统层面实现对这种标签化方案的支持,也就显得没有太大的必要,而且也会导致代码库过于臃肿,与难以维护。
152 我们已经敲定了关于责任一的落实方案:文件的表达将以多层次组织方式的树形结构呈现。接下来要讨论的就是责任二的落实。从一般情况下来看,一个文件的最为通用的操作一般有以下几个。
154 + ***打开* (Open)**  在对文件执行任何的操作之前,都需要打开文件。这么做的目的是允许VFS将该文件锁定到当前进程中,并且分配和初始化操作上下文环境,比如文件打开时使用的模式(如只读,禁用缓存,等等),或读写指针的位置。
155 + ***关闭* (Close)**  结束对文件的操作后,需要关闭文件。是*打开*的反向操作。
156 + ***读取* (Read)**  从文件读出数据。用户需指明需要读出的数据长度。读取操作的起始位置由读写指针来决定,其表征为相对于文件头的字节偏移量。该指针由VFS维护,用户可以通过*游走*操作来进行修改,但不可直接修改。
157 + ***读取目录* (Readdir)** 为读取的衍生操作,针对目录型文件的操作,一次读取该目录下的一个文件,用于枚举目录下的直系子文件。
158 + ***删除* (Delete)**  删除一个文件。该操作将会同时释放该文件在底层CFS所占据的存储资源,以及修改VFS的文件树结构。
159 + ***删除目录* (Rmdir)**  删除目录类型的文件。该目录必须为空目录。
160 + ***创建* (Create)**  创建一个文件,是*删除*的反向操作。
161 + ***创建目录* (Mkdir)**  创建一个目录类型的文件,默认位空目录。
162 + ***重命名* (Rename)**  修改一个文件的名称。
163 + ***同步* (Sync)**  将VFS中的文件缓存提交到CFS,但不保证最终的落盘(假设异步IO的使用)。
164 + ***游走* (Seek)**  允许用户间接的修改文件的读写指针,实现文件的随机访问。
165 + ***写入* (Write)**  往文件中写入数据。取决于数据写入的位置,和要写入的长度,该操作有可能导致文件所需要的存储空间的增加。
166 + ***链接* (Link)**  将当前文件用作于另一个文件的别名。
167 + ***断链* (Unlink)**  为*链接*的逆操作。
168 + ***查找* (Lookup)**  为目录类型文件的专属操作。根据给定的名称,在当前目录的所有**直系**子文件中,查找对应的文件。
169 + ***设置属性* (Set Attribute)**  设置一个属性。一个属性可以表示为键值对。假若属性值为空,那么该操作将移除属性。
170 + ***获取属性* (Get Attribute)**  根据给定的属性名,获取对应的属性值。假若属性不存在,则返回空。
172 我们已经说过,并且证明过,任何的目录都是文件。所以,上述中几乎所有的操作都要么有他的目录版本的等价——如打开和关闭,读取和删除;要么是两种文件类型共享的——如重命名,链接,断链,和两个自定义属性相关的操作。当然,也有一些是特有的,比如游走,写入和同步——这些是对于非目录文件使用的。
174 这些操作在不同的CFS中是有着不同的实现。为了将这些不同的实现从VFS的视角中抽象出来,我们可以采用面向对象的思想,将所有的这些操作抽象并且封装成接口类型——这其实也就是相当于定义了一个文件的抽象类:对于每个文件,我们除了这些抽象的操作(抽象方法)以外,我们有一些固定的成员变量,用来缓存一些比较常用的文件属性,比如大小多少,修改日期,创建日期等等。那么底层的CFS的职责就是要实现这一抽象类(提供对抽象方法的实现),并且在VFS需要操作文件时提供相应的实例化服务。在LunaixOS下面,这种文件的抽象类我们使用`v_inode`结构体——或者也叫做**虚拟inode(Virtual inode)**——去表示:
192 struct llist_header aka_dnodes;
193 struct llist_header xattrs;
194 struct v_superblock* sb;
195 struct hlist_node hash_list;
197 struct pcache* pg_cache;
198 struct v_inode_ops* ops;
199 struct v_file_ops* default_fops;
204 <summary> inode 是什么?</summary>
207 也许有不少读者在此之前都或多或少的听到过这个词汇。`inode`,或者也叫做**索引节点(index-node)**,是上个世纪七十年代末,由Unix操作系统引入的一种文件系统的实现方案,或者也可以说是“数据在磁盘上的组织方法”。
209 在这种方法中,一个文件的内容被拆分成多个大小为`512`字节的数据块儿,分散在磁盘各处(但一个文件系统应尽量保证他们的连续,以最大化空间局部性)。这些数据块儿的地址会记录在一个叫做`inode`的,固定大小的,数据结构里面;除此之外,`inode`还会记录关于这个文件的所有信息和属性。所以,从某种意义上说,`inode`其实就代表的这个文件之本身。换言之,一个`inode`就是包含多个字段(文件的元数据),以及一个长度为$k$的定长数组(用来记录数据块的地址),这样一个的结构体。假若一个文件的大小超过了单个inode所能表示的大小($512k$),那么我们就需要将一些数据块儿作为对该数组的拓展。从一般来讲,一个inode通常会在数据块指针数组中预留出一个空位,用来存放另一个指针数组的地址。相同的,这另一个指针数组也有可以做出这样的一个预留——以此类推的这样嵌套下去,嵌套的层数由文件系统的设计极限来决定。在传统的Unix v7文件系统的模型中,数据块指针数组的t拓展层数最多只有三层,分别被称之为:一级间接索引块(Single Indirect),二级间接索引(Double Indirect)和三级间接索引(Triple Indirect)。
211 当然了,除此之外,还有许多其他的文件系统实现方法。一种是**连续分配法 (Contiguous Allocation)**——这是最简单的分配法,所有文件背靠背的这么存放在一起。同时,也因为每个文件的内容都存放在连续的地址空间里,那么这也就使得这中发放享有极好的空间局部性;唯一的缺点就是,在删除文件或改变文件大小是,会导致外碎片产生。这种情况会随着时间变得越来越严重。所以,这种实现方法一般用在一些“第一次写入后就不会再动”的情况,比如CD-ROM的ISO9660就采用的是这种模式。
213 还有一种比较常见的就是**链表分配法(Linked-List Allocation)**。这个方法和`inode`有一些共同点:文件也是被拆分成多个大小为512字节的数据块。但不同的是这些数据块儿被串成一个链表,那么每个链表就对应着一个文件,而文件的元数据则是存放在这个链表的第一个节点上。使用这种分配方式的一个非常有名例子,就是微软的FAT系列文件系统。正如其名:**FAT(File Allocation Table)**,FAT文件系统是利用数组——或者叫做分配表——去实现的链表。分配表的每一个元素会记录这下一个元素的索引,以形成链表。与这个分配表共存的,还有一个被称之为 **目录索引表(Directory Entry Table)** 的表格——用来记录每个每个文件的元数据,以及对应链表的头部(分配表内起始索引)。
215 这种利用数组去实现的链表相较于原版的链表分配,在空间局部性上有了很大的提升,同时也保留有链表分配法的特性:允许文件的增删改操作,同时最小化外碎片的数量。但也有他的弱点,主要是有两点:
219 因为是链表结构,获取第$i$个节点需要遍历前面$i-1$个节点,所以,对于一个长度为$n$的链表,平均的时间复杂度为$O(n)$。
222 因为分配表是我们主要的操作对象,所以,最好的办法就是将这个分配表缓存在我们的内存中。假若我们用一个32位整数来表示表内的索引,那么对于一个小小的128GiB大小的硬盘,逻辑块大小为512字节,我们需要268,435,456个元素,也就是整整1GiB的内存——这显然是有点吓人,毕竟32位模式下我们最多可寻址的空间只有4GiB,这好家伙一下子吞掉了四分之一!
224 对于文件系统的实现方案,这里就介绍这么多。我们会在另一篇文章中进行详解。
229 + `id`: 唯一标识符,由CFS提供。
234 + `lb_addr`: 该虚拟inode对应的实际inode的LBA地址
236 + `data`: CFS绑定的一些私有数据
238 当然还有一些别的字段,只不过现在去展开讲解还为时过早,我们后面会逐个涵盖。
240 之后的`default_fops`和`ops`为两套不同的函数调用表,这些调用表为我们实现上述的文件的十四个操作提供了必须的方法。前者的`default_fops`包含了上下文敏感的操作——即使用前需要打开文件的操作。后者的`ops`则是上下文无关的操作——不需要事先打开文件就可执行的操作。
245 int (*create)(struct v_inode* this, struct v_dnode* dnode);
246 int (*open)(struct v_inode* this, struct v_file* file);
247 int (*sync)(struct v_inode* this);
248 int (*mkdir)(struct v_inode* this, struct v_dnode* dnode);
249 int (*rmdir)(struct v_inode* this, struct v_dnode* dir);
250 int (*unlink)(struct v_inode* this);
251 int (*link)(struct v_inode* this, struct v_dnode* new_name);
252 int (*read_symlink)(struct v_inode* this, const char** path_out);
253 int (*set_symlink)(struct v_inode* this, const char* target);
254 int (*dir_lookup)(struct v_inode* this, struct v_dnode* dnode);
255 int (*rename)(struct v_inode* from_inode,
256 struct v_dnode* from_dnode,
257 struct v_dnode* to_dnode);
258 int (*getxattr)(struct v_inode* this,
259 struct v_xattr_entry* entry); // optional
260 int (*setxattr)(struct v_inode* this,
261 struct v_xattr_entry* entry); // optional
262 int (*delxattr)(struct v_inode* this,
263 struct v_xattr_entry* entry); // optional
267 下面展示的是结构体`v_file_ops`的内容,也是LunaixOS目前支持的所有的文件操作:
272 int (*write)(struct v_file* file, void* buffer, size_t len, size_t fpos);
273 int (*read)(struct v_file* file, void* buffer, size_t len, size_t fpos);
274 int (*readdir)(struct v_file* file, struct dir_context* dctx);
275 int (*seek)(struct v_file* file, size_t offset);
276 int (*rename)(struct v_file* file, char* new_name);
277 int (*close)(struct v_file* file);
278 int (*sync)(struct v_file* file);
282 每个函数都是与上述列举的十四个操作对应,这里就不再赘述了。
286 我们已经是明确了文件是由`v_inode`进行抽象的。这些文件实例在目前来看只是一堆堆散落在内存各处的对象,是没有组织和结构的。为了将我们先前已经确定的树形文件组织方法应用进去,我们必须要在内存中重构出文件树的拓扑结构。这种重构的方式是被动的,这也就是说,在一开始的时候,我们可能只有一个节点——即代表根目录的根节点。而后随着用户每一次使用路径,对某个具体文件的查询中,动态的去增长这颗虚拟文件树——这其实就相当于对用户提供的每一个路径作并集。
288 
290 显然,通过修改`v_inode`使其能够参与这种树形结构的构建不是一个好主意。因为每一个`v_inode`有可能会出现在文件树不同的位置(考虑硬链接的应用,我们会在稍后的章节中详解),而这就要求我们创建出多个一模一样的对象,非常的不经济。为了解决这一问题,LunaixOS引入了一个叫做`v_dnode`的概念,**虚拟目录节点(Virtual Directory Node)**。其目的就是专门用来构建虚拟文件树的结构——是树干,并且挂载`v_inode`对象——是树上结的果实。
292 下面的代码片段给出了`v_dnode`结构体的声明。
300 struct v_inode* inode;
301 struct v_dnode* parent;
302 struct hlist_node hash_list;
303 struct llist_header aka_list;
304 struct llist_header children;
305 struct llist_header siblings;
306 struct v_superblock* super_block;
308 atomic_ulong ref_count;
314 这里的字段有点多,但我们终究会在之后的小节中全部涵盖。在目前,重要的是这几样:
317 + `inode` 该目录节点所代表的`inode`
318 + `parent` 树型结构三件套其一:父节点
319 + `children` 树型结构三件套其二:子节点
320 + `siblings` 树型结构三件套其三:兄弟节点
326 > 读者可能已经发现,用来存储目录节点名称的类型不是我们所熟知的`char*`,而是`hstr`类型,这个类型是LunaixOS对字符串的一个封装,其最主要的目的就是简化代码和参数的传递,该结构体定义如下:
337 > 在这里,我们主要封装了一些使用频率比较高的,和字符串有关的属性:
344 这种虚拟目录节点的概念除了能够让我们的架构变得简单和灵活以外,他的另一个附带的用处就是缓存——这也是为什么相同的概念,在Linux里面被称之为`dcache`,**目录缓存 (Directory Cache)**。在LunaixOS的实现里,发挥缓存的优势之关键就是在于`hash_list`字段。这是一个基于链表结构的哈希表实现——具体的原理我就不赘述了。总之,核心思想就是,当下次用户访问的路径如果和之前所有以访问过的路径有重叠,就不需要向底层CFS索要对应的目录的`v_inode`的信息,然后去构建出`v_dnode`——这也就意味着我们不需要离开内存金字塔的第三层(内存)。
346 最后就是去看看如何根据用户给出的路径去动态构建文件树。做到这一点非常的简单,我们只需要沿着用户给出的路径,从某个节点开始,一路走下去。需要说明的是,起始节点不总是根节点,在通常情况下,有这三种可能:
348 + (如果路径是相对的)当前进程所处在的工作目录节点
349 + (如果路径是绝对的)虚拟文件树的根节点,`/`
350 + 当前所处在的文件系统的根节点(关于这点,我们将会在讨论挂载点是深入)
352 整个过程其实是一个递归的方式。一个路径,给定分隔符(比如`/`),那么我们就可以写出这样的一个递归结构`<PATH> = <FILE_NAME>/<PATH>`。我们首先从某个地方开始,比如根目录,根据`<FILE_NAME>`,我们会使用前文提到的十四个文件操作中的*查询*操作,从代表目录的`v_inode`下面,根据名称,查找出对应的子文件。该操作的定义如下:
355 int (*dir_lookup)(struct v_inode* this, struct v_dnode* dnode)
358 虚拟文件系统会首先创建一个`v_dnode`实例,里面除了`name`字段——这里将会被初始化为查询的文件的名称,其余部分都是空白的。底层CFS提供的实现必须要负责填写`inode`字段和(可选的)`data`字段。如果一切都顺利。那么在之后,我们会以这个inode为起始点,继续递归的查询下去。用类python的伪代码的形式表示出来就是:
361 def lookup(start_dnode, path):
362 (filename '/' subpath) = path # 模式匹配
365 start_dnode = root_node
367 if filename in start_dnode.children:
368 dnode = start_dnode.children[filename]
370 dnode = new v_dnode(name=filename)
371 start_dnode.inode.lookup_file(dnode)
373 start_dnode.children.add(dnode)
378 lookup(dnode, subpath)
381 这个过程我们一般会给他起一个相当形象的名字: **路径游走 (Path Walking)** 。当然,上述的代码并没有处理符号链接的情况——这个我们会在之后相关的小节中涵盖。但从总体而言,LunaixOS的实现依然是遵循这上述伪代码的逻辑。路径游走的实现可以在`kernel/fs/path_walk.c`里面找到。
385 用过Windows的读者应该都对“快捷方式”的这样的一个东西感到不陌生,它允许你为任何一个文件起别名,并且可以随便放置在一个你认为方便的地方,以便用户的快速访问。同时,快捷方式还允许用户自定义图标,甚至是附加程序的启动参数——从种种方面来说,快捷方式,与其说是文件别名,倒不如说是一个可以自定义图标的脚本文件。而从这里我们也可以大致的体会出来,所谓的快捷方式并不是Windows NT内核里支持的一个功能,而是一个纯粹位于用户空间里——确切的说是Windows用户图形管理器——的功能。这也就是为什么,当我们用记事本,或者别的什么文本编辑器打开一个快捷方式的时候,我们会看到一堆乱码,而非是其指向的文件的内容。
387 
389 不过这种起别名的操作可不是Windows的专利,在Unix世界中也是存在的,并且是直接从内核层去支持的——他是属于虚拟文件系统路径游走的一部分,所以,这也就是为什么,在类Unix系统下,当我们打开一个“快捷方式”的时候,也就相当于打开了其指向的文件——别名是真正的别名,而不是用户空间里做的一种低劣的障眼法。也因为这点的不同的,“快捷方式”在Unix下面被称之为**符号链接 (Symbolic Link)**。
391 和Windows下的快捷方式有着一些表面上的相同之处,符号链接是以文件的形式存在于磁盘上的,并且是允许被用户随意放置在他或她觉得方便的地方。但是从底层上来又有些不一样:不同于快捷方式的纯二进制文件;符号链接文件是一种特殊的文件,可以被粗略的看做为纯文本文件,其内容就是所指向的文件的路径——这个路径可以是相对的,也可以是绝对的。之所以说他是特殊的文件,因为想要读取出这个文件的内容,光靠的简单的文件读写是不行的。在LunaixOS中,我们在`v_inode`里面单独封装了一个`read_symlink`函数调用,去专门用来读出所蕴含的链接。之所以作出这点区别,其主要原因是因为,符号链接的支持在可能会根据不同的CFS,有着不同的实现。对于一些天然地支持符号链接的文件系统,比如`ext`系列,他们或许会有个专门的地方去存放对应的链接;而对于一些非原生支持的文件系统,CFS驱动有可能会直接使用纯文本文件进行模拟,那么这时,读取一个链接就需要使用到普通的文件读写操作。因为这种底层实现的差别,所以一个明智的选择,就是引入单独的操作来统一所有的不一致。
393 而将符号链接整合进路径游走的过程也是相当的容易的。在LunaixOS下面,我们的主要思路是这样的:首先按照上节描述的过程去正常的进行路径游走。假若说我们遇到了一个符号链接文件,那么我们就去调用`read_symlink`来读出里面蕴含的链接,而后以该链接位路径,符号链接文件的上级目录为起始节点,*递归地*进行路径游走的过程,及至我们完成对路径的游走。当然了,这个游走可能是无穷无尽的——比如说我们在创建符号链接时犯了个错误,不小心形成了环路——那么这需要我们对递归的深度加一个限定,在超出这个限定的时候返回错误代码(Linux下会返回`ELOOP`,这在LunaixOS中也是一样的)。上述过程可以非常简单的整合进我们上节提供的路径游走伪代码中:
396 def lookup(start_dnode, path):
397 (filename '/' subpath) = path # 模式匹配
400 start_dnode = root_node
402 if filename in start_dnode.children:
403 dnode = start_dnode.children[filename]
405 dnode = new v_dnode(name=filename)
406 start_dnode.inode.lookup_file(dnode)
408 start_dnode.children.add(dnode)
410 + if dnode is symlink:
411 + if depth excess the limit:
413 + link = dnode.read_symlink()
414 + dnode = lookup(start_dnode, link)
415 + start_dnode[filename] = dnode
420 return lookup(dnode, subpath)
423 需要注意的是,添加的最后一行代码:`start_dnode[filename] = dnode`,是相当于做了一个子树置换的操作。这主要是为了最大化我们缓存的参与度。但是这样以来会有一个问题,那就是当我们处在符号链接指向的子树根节点时,我们使用`..`是无法返回符号链接所在的目录的,相反,是返回到被指向的子树根节点的父节点。这听起来有点绕口,那就让我们举个例子吧!
425 
427 如上图所示,假设D是位于A目录下的一个符号链接,其指向的是位于I目录——在别的一个什么地方——下的目录K。为了最大化缓存的参与度,我们在解析后,令原本属于D的位置指向D所指向的目录K。显然,这条短路是一个单程票。不过这并不是什么非常严重的问题——事实上,这是完全符合`..`的定义——即指向当前目录的父目录。这也就是为什么,在Linux环境里,如果我们将一个包含符号链接的路径使用`setcwd(2)`设置为工作目录,而后使用`getcwd(2)`重新读出,我们会发现那是一条完全不同的路径(读者可以自行验证)。而与之相反的是我们平时在Shell环境里观察到的行为——即使用`..`能够从符号链接的目录退出去——这其实是一个来自用户空间的障眼法:shell将用户`cd`的目录路径和当前工作目录的路径拼接起来,而后进行字符串操作,将所有的`..`移除,比如,输入`a/b/c/../d`,就加工成`a/b/d`。而后将这些加工好的字符串作为新的工作目录。这点细节是读者们必须要注意的。
429 但是上述的子树置换的操作有一个非常值得注意的问题:在后续的访问中,我们就会在虚拟文件树层面上丢失对D本身的访问。那么这样一来,当用户使用`readlink(2)`想要读取符号链接文件D所蕴含的链接时,操作就会失败——因为此时名称D已经代表的是目录K。
431 要想解决这个问题,我们可以使用另一种方法(方案一),那就是我们保持D本身,然后在`v_dnode`的定义中添加一个专门用来指向被链接目录节点的指针——比如`struct v_dnode* symlink_to;`成员字段。但是这样会导致一个新的,但是更加严重的问题,那就是——假设被指向的目录在某个时间点被删除,或者被VFS的垃圾回收机制释放了(我们会在后文深入这个机制)。因为是单向引用,反向查询的性能代价太高,显然不现实,那么`symlink_to`就变成一个危险的野指针,从而直接危害到系统的稳定性。
433 当然了,办法总比困难多。既然是单向引用导致的`symlink_to`指针过时的问题,那么我们可以位每个`v_dnode`加一个链表,用来记录所有指向他的符号链接节点——比如`struct llist_header symlink_sibling;`和`struct llist_header symlinks;`成员字段。这的确是一个可行的方案(方案二),但这样一来,会显得有些过于臃肿和复杂。因为这相当于我们需要同时维护两个完全不一样的树:虚拟文件树和符号链接树。
435 最后一种办法(方案三)就是直接不做缓存方面的考虑,即没有子树置换,没有单独的链接指针,也没有维护两个树的操作。当然,我所说的“不做缓存考虑”,指的是“不做虚拟文件系统层面的缓存考虑”。这就意味着,底层的CFS必须保证对`read_symlink`函数调用结果的缓存。
437 尽管如此,LunaixOS在目前还是用的我们最初的子树置换的方案。不过根据上述的讨论,我们会在后期使用最后一种方案,因为其重构的压力会比较小,但是这也会导致递归解析会在每次路径游走时变得不可避免,从而在空间复杂度和时间复杂度上有所提升。可是和方案二比起来,这样做值得么?这是一个非常巧妙地问题,还有待分析。但对于现在来讲,这点微小的性能差别我们可以忽略不计。
439 除了符号链接,另一种链接方式就是 **硬链接 (Hard Link)** 。从表层来看,两种链接都是属于“文件别名”的范畴,其功能性也是一样的。但从本质上来看,硬链接是直接影响到磁盘上的文件组织的拓扑结构,而不像符号链接只是存放了一个路径——比如对于FAT来讲,硬连接的表示就是不同的目录项(Directory Entry)指向文件分配表中的同一项;对于inode来讲,就是不同的路径表项(Path Table Entry)指向同一个inode节点。
441 由此,我们其实也就可以很好的总结出符号链接和硬链接之间的区别了。首先最重要的一点就是符号链接是逻辑层面的文件别名,而硬链接可以看成是物理层面的文件别名。也因为这一点的缘故,符号链接是可以跨越文件系统的边界,而硬链接,显然,只能位于同一个文件系统。到这里,读者也就不难看出,硬链接从性能上来说是要比符号链接更为高效,因为这个别名的过程是对软件完全透明的。
445 操作任何一个文件之前都需要打开它;结束文件的操作之前都需要关闭它——这是一个程序员必须懂得的最基本的礼仪,一切都须有始有终。也因为这样,LunaixOS也需要存在对文件的打开和关闭的系统调用支持。
447 也许有人看到这里会觉得很不可理解,难道仅仅因为这个惯例就去支持文件的打开和关闭?或者说是,我们为什么需要打开文件然后再去操作,不能直接使用`v_inode`中提供的方法进行操作?
449 如果让我来回答这个问题,我会说,打开一个文件其实就等同于为接下来的操作,创建了一个单独的上下文环境。那么一个上下文环境里面都有什么?其中一个最为明显的,也是大家非常熟悉的东西就是文件的位置——即读写指针距离文件启示部分的位移字节数。然后就是这两样:
452 + 文件的内存映射记录(Lunaix暂未支持)
454 注意,这里出现的调用表可不是简简单单重复inode里面的调用表,在打开的一个文件时,Lunaix VFS会来一个偷梁换柱,将调用表里面对文件读写的操作重定向到页缓存,然后在拷贝到这个“文件上下文环境”的调用表里面,这也就是说,所有的读写的数据都会默认地被缓存起来。也处于这一点原因,inode里面的操作调用表又叫做 **默认操作调用表** ,里面所有的操作都是直接由底层cfs提供的。当然,你也可以绕过这个缓存,比如在打开的时候指定`FO_DIRECT`开关(对应着Linux里面的`O_DIRECT`)。页缓存的具体细节我会在后面详解。
456 那么,我们也就可以直接的,并且不带进一步解释的,列出这个上下文环境的结构:
461 struct v_inode* inode;
462 struct v_dnode* dnode;
463 struct llist_header* f_list;
467 struct v_file_ops ops;
471 而到这里,各位应该也就不难发现,`v_inode::ops::open`就是用来初始化这一结构体的inode操作(也就相当于打开了文件)。整个打开的过程可以参考`kernel/fs/vfs.c::vfs_open`。
473 创建好了操作上下文环境,那么我们需要找个办法能够让上层用户对其进行引用,好用于之后的操作。在这里,我们会给用户分配一个文件描述符——这是一个整数,是进程描述符表内的索引(也不难猜到,那儿存放着所有该进程打开的文件描述符)。当然了,文件描述符可不是我们前面所说的`v_file`;事实上,他是另一个结构体:
483 这里的`flags`为打开这个文件时所传入的开关项和选项。
485 那现在就来看看整个`open`系统调用的实现:`kernel/fs/vfs.c::vfs_do_open`
487 但这还是没有说明我们为什么要定义另一套结构体,去最终指代已经打开的文件,而这个结构体似乎只是用来指向另一个结构体。虽然说这样作的好处是将文件打开时的传入的flags隔离开来,但是,为了更好的说服大家,这里我们可以来考虑一下IO重定向的问题。用过Linux的都知道,我们可以将stdout重定向到某个文件。比如在bash下,我们可以`echo 'abc' > a.txt`;或者在C代码中,我们可以使用`dup2(2)`这个系统调用来完成这一伟大的任务:
491 int file_fd = open("a.txt", O_CREAT | O_TRUNC | O_WRONLY);
498 而实现这一点(`dup2(2)`)就变得相当的简单,我们就仅仅只需要将`v_fd::file`的指针修改过去。同时,因为我们的文件操作的flags是保存在`v_fd`里面的,所以我们依然能够保留我们在创建这个文件描述符时,所赋予的一些特性,而不用关心他到底指向哪一个文件。
500 当文件操作完毕的时候,我们就需要关闭这个文件。这个关闭的操作除了释放先前分配的`v_fd`和`v_file`结构体,还需要:1) 清除所有由`mmap(2)`建立的内存映射关系;2) 将已修改的缓存页面进行回写。(注意,这是LunaixOS一个不同于Linux的设计,在后者中,文件的关闭**并不能**保证数据真正的写入硬盘)
503 > 当然,`v_file`结构体的释放要更为复杂一点,因为我们要考虑到IO重定向的问题,也就是说被`v_fd`引用的数量。毕竟我们不可能仅仅因为其中一个文件描述符的关闭,而去直接释放`v_file`,从而导致其他引用此`v_file`的文件描述符忽然成了无头的苍蝇,在内核的地址空间里乱窜。
505 > 所以,出于这一点的考虑,在`v_file`里面增加一个引用计数器是非常必要的。
510 从前面的讨论中,我们可以看到,任何文件系统都存在多层级表示法的抽象,哪怕是标签化文件系统也是如此——事实上,树型表示方法是文件系统的定义之一。那么这样一来,我们也就可以做出如下的断言:每一个文件系统都等价为一棵独立的树。因为树形结构特有的递归性质,树与树直接可以通过共享相同的一系列节点组合到一起,成为一颗单一的树。那这也就给了我们责任三的落实方案:以VFS中的虚拟文件树为树干,任何的文件系统都可以作为子树,接入到任何已存在于虚拟文件树的子树节点——一般是空目录,那么当用户在虚拟文件树中游走的过程中,也就自然感受不到文件系统之间明显的边界,实现底层实现与上层逻辑的完全解耦合。而这个承担起所有重任的,作为接入点的子树节点,则被称之为**挂载点 (Mount Point)**。
512 我们举个简单的例子,下图展示了一个简化的Linux系统根目录`/`下的情况。在这里,`media`和`home`原本是隶属于 **根文件系统 (Root Filesystem)** 中的两个空文件夹。按照Linux的约定,`home`文件夹将会作为存放用户数据的地方,`media`则用来包含任何接到电脑上的可移动存储设备。当系统启动后,用户将一个载有ext4文件系统的磁盘挂载到`/home`目录下。此时,原本位空文件夹的`home`目录就变成了一个访问这个ext4文件系统的门户。而这样一来,原本ext4文件系统的根目录就变成了`home/`,任何对`/lxsky/notes.txt`的访问,就必须要写成`/home/lxksy/notes.txt`——这对于虚拟文件系统的路径游走机制和上层用户是完全透明的,因为在此时他就是虚拟文件树的一部分。所以这也就是为什么,挂载点的概念能够*最大程度*地消除文件系统之间的边界感。
514 
516 同样的,这对于`/media/usb`也是如此。在这里,`usb/`和`file`分别是文件夹`media`下的子文件夹和文件,他们都隶属于根文件系统。其中,`usb/`作为一个用来访问来自Windows用户的大容量U盘的挂载点,也就是通往NTFS文件系统的门户。
520 > 万物都要有始有终,递归也要有教他停止的Base case。所以,基于树结构的递归性而产生的挂载点之概念,也要有一个停止的地方——这个地方就是根文件系统,也可以说是整个系统的第一个挂载点,一个没有挂载点的挂载点——总之,根文件系统存在的唯一目的,就是为其他挂载点提供“住的地方”,是他们存在的大前提。
522 > 根文件系统的选择方式非常之多,像笔者的Ubuntu上面就是一个实实在在的,以ext4作为文件系统的,磁盘分区——而这也就能允许用户在根目录下面创建普通的文件(尽管是极其不推荐的!)。当然,你也可以选用基于内存的伪文件系统——LunaixOS就是用的这种方法。下面展示的一段是来自`kernel/k_init.c::_kernel_init`方法里面的代码摘抄,是LunaixOS在启动后最先做的事情之一。
525 if ((errno = vfs_mount_root("ramfs", NULL))) {
526 panickf("Fail to mount root. (errno=%d)", errno);
530 值得一提的是,挂载点这种概念并不是类Unix系统独有的特性。相反,在最不可能的Windows下也有着一模一样的概念。不知道大家有没有注意过,当我们使用Windows的磁盘管理器创建新加卷的时候,在最常用的盘符设置选项下面,有着一个“不起眼”的文本框——这也是许多普通用户经常忽略的。而这就是Windows下的挂载点功能!也是当所有盘符(A-Z)都被分配完后,Windows会使用的后备方案。正如同下面这张图所展示的那样,我们可以看到,不同于类Unix系列的系统,其挂载点是任意目录;Windows下的挂载点则是仅限于NTFS文件系统下的目录。而这,为总体的灵活性打了个极大的折扣——不过考虑到Windows下面除了NTFS和FAT以外,似乎也没有什么其他文件系统的选择,对灵活性的批评也就显得相当的鸡肋了。
532 
534 ### LunaixOS下的挂载点解决方案
536 前面对设计方案的大篇幅的讨论和论证终于没有白费!`v_inode`和`v_dnode`概念,其实已经是自动支持了挂载点之概念:所有的文件系统都会将他们的实现绑定到“抽象类”,`v_inode`里面;而`v_inode`又由`v_dnode`统一的组织到虚拟文件树上,整个底层的实现的对上游组件来说是完全透明的。
538 但是别高兴地太早,想要真正开始投入使用,有几个问题还亟待解决:
540 + ***文件系统的卸载和挂载*** 这是一个自然地问题。上述我们只是讨论了挂载点的定义以及在当前设计下的可行性。然而具体挂载上取得的方法还亟待确定。
541 + ***底层文件系统上下文环境的区别***
543 对于第二点,也许没有那么显然。挂载点的概念使得CFS的存在对上层用户透明,可是我们仍然需要一个区分的办法——这主要是用来执行一些*和文件系统本身相关的操作*。这是什么意思呢?举个简单的例子,当我们需要创建一个文件的时候,CFS可能需要为这个文件分配一个空间——对于FAT来说,就是分配一个分配表中空闲的表项;对于inode,就是分配一个空的inode槽位——这个分配所用到的信息是有着很强的上下文相关性的,不同磁盘上的情况都不一样,是和文件系统本身相关的,而不是文件。那么像这一类的信息就被统称为文件系统的元数据,一般位于文件系统数据的最前面,是启动扇区之后的第一个逻辑块。也因为这一点,我们一般称之为**超级块(Super Block)**。
545 
547 一个文件系统元数据并没有一个特别统一的格式,不同的文件系统可能需要不同的信息作为元数据,不过一般而言,都会有几个类似的信息:
554 除去这些以外,一个CFS驱动可能还需要对应的存储设备驱动的信息。但不管怎么样,我们都需要找到一个携带这种元数据的办法。有两个办法:第一个办法是利用`v_inode::data`来进行携带。但是这种办法又重新将文件系统的数据和文件的数据耦合在一起了,这显然是和我们前面所讨论的背道而驰。所以我们就只能另外存放了,而这也就引出了第二种方法,一个单独的虚拟超级块,`v_superblock`结构体——这个也就是我们在文章开头时所说的,由工厂创建出来的实际文件系统实例了:
559 struct llist_header sb_list;
561 struct v_dnode* root;
562 struct filesystem* fs;
563 struct hbucket* i_cache;
566 uint32_t (*read_capacity)(struct v_superblock* vsb);
567 uint32_t (*read_usage)(struct v_superblock* vsb);
568 void (*init_inode)(struct v_superblock* vsb, struct v_inode* inode);
573 这里出现的大部分成员的含义,其实是相当的直观了,我就不在一个个描述了。关于`struct device`的实现我将会在关于实现设备子系统的文章中详解。有几个是值得注意的:首先是`i_cache`,这个是关于inode缓存的,我们将会在之后关于VFS缓存系统的章节中说明。然后是`ops::init_inode`,顾名思义,是允许CFS提供自己的inode初始化方法。VFS会在创建完inode之后自动调用这个方法,这个主要是方便CFS将这个逻辑抽象出来。最后就是`fs`,位CFS工厂的实例,也是挂载点这个概念中的重点。
575 在深入讲解这个概念之前,首先来看看其定义:
580 struct hlist_node fs_list;
584 int (*mount)(struct v_superblock* vsb, struct v_dnode* mount_point);
585 int (*unmount)(struct v_superblock* vsb);
589 根据设计,每一个LunaixOS支持的CFS都必须要使用`fsm_register(struct filesystem*)`,向文件系统管理器注册这个结构体。其中,`fs_name`,`mount`,`unmount`是必填项,其他项目由文件系统管理器在注册时自动填充。对于这三个必选项,第一个项目的含义自然就是文件系统的名称,比如`"ext2"`,`"iso9660"`。然后就是两个关键的方法,`mount`和`unmount`。这两个函数会在该CFS被挂载和卸载时调用,这也就是相当于工厂模式下用于实例化的工厂方法,以及对应的解构器。
591 在挂载时,VFS会首先锁定即将作为挂载点的目录节点。如果该目录非空,则会子目录节点移除——需要注意的是,这个操作并不会移除实际的文件。实际的子文件树还是存在的,只不过在我们卸载挂载点之前这段时间,是不可访问的——然后,VFS会分配一个虚拟超级块`vsb`,并连同目录节点一同传入`mount`进行挂载。
593 在这里,CFS驱动必须要设置vsb,并且将其根目录的`v_inode`挂载到挂载点目录节点上。而这个操作将会覆盖原有的`v_inode`,那么当后面我们卸载该文件系统的时候,作为挂载点的目录节点就会失去了他的CFS信息。也正是因为这一点,我们在卸载时除了调用`unmount`方法让CFS进行收尾工作以外,还需要将这个先前作为挂载点目录从虚拟树中移除,从而教VFS在用户下次访问时重新创建。当然,我们也可以找个什么地方将原来的`v_inode`保存起来,而后再恢复。但相较于前面的方法来看,明显是有点复杂了。
595 关于挂载与卸载的实现,读者可以在`kernel/fs/mount.c`中找到。
597 那么这也就是我们的挂载点的实现思路了。但我们还没完事,因为上述的实现有些极其严重的问题:
600 一个进程的工作目录,或者打开的文件,有可能是位于某个挂载点内部,那么这样一来,该挂载点就可以算是处在繁忙状态。对于这种挂载点,自然是不可以轻易地卸载。
602 因为树结构的递归性,一个挂载点下面有可能存在另一个挂载点。对于这种问题,我们也不可以轻易地卸载。
604 虽然在目前来看不是我们所面临的的问题,但确是非常值得去思考,因为这个问题是由上述的子挂载点问题引申出来的。为了看到这一点,我们假设目录A是一个挂载点,以及挂载点A所代表的子树中的某个子目录B。如果我们将A挂载到B上,那么就会出现一个环路。这就导致A和B互为对方的子挂载点,从而使得A与B均不能被卸载——这是一个相当经典的循环依赖问题!但是我们也知道,每一次我们执行挂载,我们都相当于创建了一个全新的CFS实例,而挂载点这个概念也不会反映到CFS中——他只是一个来自抽象层的概念。
606 所以在目前的LunaixOS的挂载点实现中,这个问题是不可能出现的。但这确是Linux所面临的一个问题,这是因为Linux内核在2.4版本中引入了一个被称之为 **绑定挂载 (Bind Mount)** 的概念,它将被挂载者的范畴从文件系统延伸到了任意的目录,也就是说你可以将一个目录作为另一个目录的别名——这和符号链接或硬链接不一样,绑定挂载不会反映到CFS中,但是后者会。
608 为了解决种种上述问题,这就需要我们去建立挂载点和挂载点之间的关系,于是就有了**虚拟挂载节点**,`v_mount`的定义:
614 struct llist_header list;
615 struct llist_header submnts;
616 struct llist_header sibmnts;
617 struct v_mount* parent;
618 struct v_dnode* mnt_point;
619 struct v_superblock* super_block;
620 uint32_t busy_counter;
625 这个虚拟挂载节点最主要的部分就是维护了一个挂载点的层级结构——`submnts`,`sibmnts`和`parent`,分别对应着子挂载点,兄弟挂载点以及父挂载点。同时还有一个`list`来方便我们以链表的形式访问到所有的挂载点。整个挂载点的结构可以看成是虚拟文件树结构的一个映射,是会随着用户的挂载卸载操作动态的,实时的发生改变。
627 
629 这种结构的表示能够允许我们去快速发现任何环路的存在,于是也就未雨绸缪地解决了第三点的问题。而至于第一,第二点问题的解决,关键就在于`busy_counter`这一计数器的使用。这个计数器用来跟踪挂载点的“繁忙程度”,对应着两个互为镜像的方法:用来增加计数器的`void mnt_mkbusy(struct v_mount*)`以及递减计数器的`void mnt_chillax(struct v_mount*)`。
636 > 
639 上述的两种方法,将会在文件的打开或关闭,工作目录锁定或解锁,以及子挂载点的挂载或卸载,这三种情况下,分别执行。一个挂载点当且仅当计数器归零时,才可以被卸载。同时,由于第三种情况——子挂载点的挂载和卸载——的考虑,一个递归引用的得以保证,是解决子挂载点问题的关键。为了看到这种引用的重要性,我们可以举个例子。假设我们有挂载点A,B,C和D。其中,挂载点B和C是挂载点A的子挂载点,而挂载点D是B的子挂载点,那么B,C,D就都可以看做是A的后代挂载点。因为A有两个挂载点,所以A的计数器为2;C只有一个,那么为1。那么这样以来,我们要想释放A,那么就必须释放B,从而也就要求我们释放C。相反的,假若我们没有这种引用,那么A就可以直接被释放——而不管子挂载点的存在与否。
643 让我们来考虑一下文件读写的操作。假设我们有一个长度为$n$的数据需要写入`/dev/sda`,而这个文件——用过Linux应该会相当的熟悉——其实就是我们硬盘设备在文件系统中的映射。任何对这个文件的读写操作,其实就等同于对该文件代理的硬盘的读写。而做到这一点其实非常简单,我们只需要将让两个`read`和`write`的函数指针指向对应的磁盘读写调用,而不需要对上层调用做出任何的改动——面向对象的好处!
645 我们知道,磁盘读写的操作是按照每个扇区来进行的。那么,这也就要求我们去将整个长度为$n$数据进行拆分,然后去写入——这完全没有问题,实现起来也相当的简单。同样,如果说我们需要将我们刚刚写的数据读出来的话,那么也是类似的:以扇区为单位,读出数据,最后整合到一起。那么总结一下,就是:单一的数据流拆分成分散的数据流;分散的数据流整合到单一的数据流——这其实就是一个非常经典的 **集散式I/O (Scatter/Gather I/O)** 模型。
647 但是不管怎么样,我们都会发现,这其实是一个相当低效的方式。因为每一次的读和写都需要对硬盘操作一次,哪怕我们要读取的是我们刚刚写入的数据,或者是我们写入数据的一部分。换言之,我们在这里希望能够让一切的读写享受到空间局部性所带来的便利和高效。为了做到这一点,我们需要一个缓存。
649 那么缓存要多大?这几乎是一个天经地义的问题。如果说我们分配一个固定大小的缓存,比如说我们规定大小是`4096`的倍数——在x86平台等大多数平台下,这就是相当于按页去计算。有了这层缓存后,那么我们上述情景的读取操作就可以直接从缓存里拿取数据,而不用打扰下面的硬盘——空间局部性得到了完美的利用!但是这样一来,我们又无法满足时间局部性:如果说在读取之后,我们又从硬盘的其他地方读了一些数据,那么自然而然的,我们的缓存就需要装填这些新的数据。而这么已来,当我们需要重新读取我们刚开始的那个数据,我们就无可避免的需要从中硬盘拿取这个我们曾经有过的数据。这显然是有些不划算。
651 那么使用更大的缓存呢?从理论上说,是可以的。但是这极不现实,原因有两点:1) 你永远也不知道你应该分配多少才合理——分配少了,时间局部性很差;分配多了,却浪费了宝贵的内存资源。2) 你的电脑内存没那么大地方。而且,用这种固定缓存的方式,会给你的实现带来一些麻烦,比如说,你如何确保你缓存里的数据就是你要读取的数据,换句话说,你需要将缓存里的数据和你目前的文件位置建立起联系。
653 将这些全部需要考虑的因素放在一起,我们可以发现,CPU里面的分页机制似乎是一个非常好的解决方案,比如他的下面几点特性:
656 当我们尝试访问的地址位于一个不存在的页时,就会触发page fault中断——用x86架构的叫法就是14号中断。那么在这时,我们就可以去动态地分配这个页。同样,如果说我们试图读取一个不存在于缓存的数据时,我们可以去动态的分配一块儿缓存,然后去从磁盘进行拿取——整个过程对于上游用户是完全透明的。Address in, data out, what a magic!
658 从按需分页机制中可以发现,出于其动态性,我们的缓存不需要一次性就分配完成,而是动态地,离散地,去增长。
660 分页机制通过将虚拟地址,按层级地拆分成对应的层次的页表索引,实现连续的虚拟地址到离散的物理地址的转换。同样,我们也可以定义一种类似的方法,将连续的文件读写的位置,转换为离散的缓存块儿地址。
662 前面两点就好说,麻烦的就是地址转换的部分。在分页里面,CPU使用两个层级的页表来实现这个转换(这里假设二联页表,即32位分页),整个占用的空间,哪怕你只是映射了一个物理页,最少需要2KiB的内存当然,硬着头皮用肯定是没问题的。不过,我们还能做的更好!
664 怎么做?这其实就相当于一个稀疏矩阵(Sparse Matrix)的实现。现在,让咱们来调动一下已经生锈的大脑,就当这是某个Leetcode题目,来找找头绪。首先,可以确定的是,不可能用链表的形式,毕竟你每次获取一个缓存块的复杂度是$O(n)$,其中$n$是缓存块的数量。这里由两个办法:第一个是利用哈希表,第二个就是利用一种叫做前缀树的东西。我们这里将会探讨后一种方法。
668 我之所以选择这套方法的原因其实非常简单,不是为了炫技,而是这种前缀树方法的原理,和分页机制里面的地址转换几乎是一模一样。
670 不过,我不想照着算法教科书在这里给大家生搬硬套前缀树的概念和性质,因为这的确是非常的无聊,也不很接地气。相反,让我们将其放进我们的文件系统的情景里去讨论。现在,假设我们有一个类型为`uint32`的整数,代表的是一个地址,一个位置,一个位移……等等诸如此类的。和分页机制一样,我们把这个整数的32个比特进行分区,比如每4个比特为一组,于是就有了8组:
673 \overset{1}{\fbox{$\times\times\times\times$}}\ \overset{2}{\fbox{$\times\times\times\times$}}\ \overset{3}{\fbox{$\times\times\times\times$}}\ \cdots\ \overset{8}{\fbox{$\times\times\times\times$}}
676 如下图所示:如果我们令每一组代表树的一个层级,而这每一组比特所表示的数字,$n_i$,为下一层级所属的子树节点的编号——不难猜到,最后一组比特就是这这棵树的叶子节点的编号。而这样一来,我们就会得到一个深度为8的,完全16叉树。情理之中:其总共的叶子节点数量为: $16^8=2^{32}$ 。
678 
680 那么对于这种树,我们叫做**按位前缀树(Bitwise Trie)**。
682 所以我们也不难看到,对于一个 $k$ 位的整数,如果以每 $m$ 位为一组,其中 $k\equiv0\ (\text{mod}\ m)$,那么从最高位处开始的前 $k/m-1$ 个组别,就构成了一个前缀,定义了一条通往最终叶子节点的一条路径。这样一来,当一个新的整数需要被表示的时候,我们只需要逐个遍历所有组别,从根节点出发,逐层往下,有路就走,没路开路,及至我们到达最后一个组别,也就是最终的叶子节点。
684 一个很自然的问题:这套方法有什么好处呢?从空间复杂度来说,每表示一个整数,我们需要创建出一堆额外的对象用来作为节点的表示。从最坏的情况来说,所有的32位整数就需要 $16^9-1$ 个节点。就算我们以分页机制为榜样,每个页缓存大小位4KiB,砍掉末尾的12位,我们依然还需要 $16^6-1$ 个节点。这些额外的内存用量,似乎还不如直接硬性分配4个G的内存呢!
686 的确是这样的,这其实正是典型的空间换时间的例子。前缀树——正如同他的名字,非常简单的,我们可以看到,从里面检索一个已经存放进去的整数 $n$ 的时间复杂度为 $O(\log_{2^m}n)\Rightarrow O(\log_2n)$ ——啊哈,人人最爱的对数时间!远远比基于链表的实现好多了。当然,顺带一句,多亏了空间局部性,基于前缀树实现的页缓存机制在**一般的情况**下其实也可以说是空间高效的(space-efficient)。
688 不过上述的方法其实还可以继续改进。我们可以看到,上述的算法仅仅只是将一个32位整数进行无脑的,逐比特的分区——这种定长的前缀在理论上是没有任何问题的。但是,如果我们把这种情况放在实际应用中进行分析,事情会有些不一样:在大多数情况下,被操作的文件几乎不会很大,所以这就导致一个表示位置的整数会出现大量的前导零。而这些前导的零除了会占用额外的几个节点,为我们查找时增加几次完全多余的循环次数以外,没有任何的一点用处。那么最好的办法就是去考虑“最长有效前缀”而不是之前简单的“前缀”。
693 > 这个其实也是因人而已。在笔者的`/home`挂载点下的文件平均大小大约为81149字节,那么这也就是相当于在平均情况下,令$m=4$,每缓存页大小4KiB,于是就有差不多6个节点被白白的创建,6次的循环被白白的执行。
695 > 有兴趣的读者可以使用`find ./ -ls | awk '{sum += $7; n++;} END {print sum/n;}'`去看看自己目录下的所有文件的平均大小。
698 换句话来说,我们希望将任何前导的零压缩为一个组别,就像这样:
701 \overset{1, 2}{\fbox{0000 0000}}\ \overset{3}{\fbox{$\times\times\times\times$}}\ \cdots\ \overset{8}{\fbox{$\times\times\times\times$}}
704 但是这样一搞,叶子节点就会有存在于每一层的可能,而不是最后一层。这非常的麻烦!假设我们有一个稍短的前缀 $x$ ,其指向的叶子节点位于中间的某一层;如果碰到一个更长的前缀 $y$ ,其中 $x\in y$ ,那么我们就必须得要重新安置 $x$ 的叶子节点,这将需要对树进行非常复杂的结构调整。在这里,为了实现的简单,我们规定每一个节点——不论是子树节点还是叶子节点,都可以存放数据——或者说是,每个子树节点都会有一个内部的叶子节点。于是我们也就有了如下的结构定义:
710 struct llist_header children;
712 struct llist_header siblings;
714 struct llist_header nodes;
715 struct btrie_node* parent;
723 我们也需要一个专门的结构体来表示整个树(用于存放整个树的根节点):
728 struct btrie_node* btrie_root;
734 在LunaixOS中,完整的前缀树实现可以参考`kernel/ds/btrie.c`
736 剩下的一个亟待处理的问题是参数的选择。在这个算法中,我们只有一个参数 $m$ 需要确定。不同的 $m$ 选择会直接影响到我们最终的时间-*空间*复杂度的平衡。注意,这里我说的*空间*复杂度并不是节点所占用的总空间——因为节点所占用的总空间永远是独立于$m$的;而是我们在递归时所产生的栈调用,换言之,就是树的高度。那么我们最终要追求的平衡也可以这么描述:是否能找到一个合适 $m$ ,使得我们花在遍历检查子节点上的时间(横向遍历),与我们花在遍历层数上的时间(纵向遍历),达到某种平衡?一个非常极端的例子,令$m=0$,这样我们的前缀树就会退化为一个链表,反之亦然。
738 为了找到这个 $m$,我们需要用一点数学。为了方便我们的推导,我们假设每个单独的指令(动作)需要单位时间去处理。因为每个子树节点所包含的儿子节点最多为 $2^m$ ,对于第 $n$ 个元素的处理,该算法的所需要的时间以 $T(n|m)=\frac{1}{m}2^m\log_2n=T_vT_h$ 为上界。其中,横向遍历时间,$T_h(n|m)=2^m$;纵向遍历时间,$T_v(n|m)=\frac{1}{m}\log_2n$。总时间,纵向横向时间全部画在一起就如同下图所示。我们分析的思路就是以 $T_h$ 基准点,而 $A$ 和 $B$ 是 $T$ 和 $T_v$ 距离基准点的位移。可以看到,当 $T$ 在 $T_h$ 之下($A<0<B$),那么这就说明我们目前所包含的数据连一层都没有填满,同样,我们继续往上走,及至 $T$ 在 $T_h$ 之上,但是 $0<A<B$。这就说明,我们前缀树里面至少已经包含了一层的数据($2^m$),横向和纵向遍历的时间差处在在一个合理的范围内——这是我们想追求的一个情况。那么相反的,当 $0<B<A$ 时,这就意味着——横向或者是纵向时间——这之中的其中一个主导了我们的整个总时间的变化。这不是我们想要的。
740 
742 所以,我们希望寻求一个 $n$ 与 $m$ 之间的关系,使得 $A=B$ 成立。那么 $n$ 就定义了理想的文件大小的上界,于是我们也就得到了我们的希冀的 $m$。
747 \left|\frac{1}{m}2^m\log_2n - 2^m\right| = \left|2^m - \frac{1}{m}\log_2n\right|
750 现在我们求解$n$关于$m$的表达式。我们知道当 $n < 2^m$ 时,情况是显而易见的,所以我们这里只讨论$n \geq 2^m$的情况。根据这个限定,我们能够确定该方程有且仅有一个解,所以我们可以直接拿掉绝对值。最后通过对 $n$ 进行化简我们可以得到我们想要的:
753 n(m)=2^{\frac{2^{m+1}}{1+2^m}m}
756 以笔者自己的电脑举例子,根目录下平均文件大小大约是$7\times 10^7$字节。假若这也是我们LunaixOS会面临的情况,考虑到我们使用的是4KiB的页面作为缓存,所以 $n=17090$,我们可以求解出 $m$。关于这个方程的求解,有些困难,但我们可以利用一些软件去实现,比如WolframAlpha。我们得到结论,在这种一般情况下面,$m=7.05$,向上取整到2的倍数,$m=8$ 最为合适。
758 在目前LunaixOS的实现中,我们令 $m=4$。
762 我们在前面已经说过,页缓存最主要的功能是允许我们在文件读写的操作中收获一些空间局部性带来的性能提升。对于任何可缓存的文件——这个有两点来决定:第一点是该文件的打开操作是没有被`FO_DIRECT`修饰的(Linux下面也有类似的选项,即`O_DIRECT`);第二点是要求该文件必须为块文件而非序列文件——关于这两种文件类型的含义,我们会在之后关于LunaixOS设备子系统的文章中了解到,暂时毋需担心。言归正传,对于这一类能够缓存的文件,LunaixOS会尝试缓存所有我们触碰到的文件的4KiB区域——这也就是说,当我们使用`seek(2)`将读写指针移动到某个新的位置,并进行读取,如果这个位置不存在于任何已缓存的页中,那么根据当前的设计,虚拟文件系统会分配一个空白的页,而后操作CFS去用文件的数据填充这个页。这个数据的范围是由当前读写指针的最近的上下4KiB边界定义的。
764 而对于写的操作来说,情况也是差不多的。对于任何不存在的页缓存,我们会先分配处一个空白的页。区别就在于这里不会去做任何的填充,而是直接执行写入操作。但这么一来,那些没有因为写入操作影响,却位于页缓存范围内的数据,就会在缓存回写的时候,被彻底的覆盖掉。所以,一个合理的实现似乎应该是这样的:现将数据拉去进来,然后再写入,于是我们也就可以保证数据的完整性,和操作的一致性了。
770 每次写入还得事先执行一次读取操作。这也就相当于,一次文件的写入相当于两次的IO操作——读取是第一次,缓存回写为第二次。
773 在很多情况下,文件的所有写入操作基本上都是进行对文件的追加,或者是对文件的全部覆写。反观像修改文件的某一部分——而且是极小的,可能只是几个字节的部分的——这样的应用场景实在是过于少见。况且,这种修改部分内容的行为其实是完全可以在用户空间中实现出来的——这应该是用户程序的责任,而不是内核的责任。那么我们也就没有必要以性能位代价,去支持一个几乎不怎么常见的场景。
775 为了保证实现的简单性,缓存回写也是按页来进行的,而非是页中实际存在的数据(事实上,我们根本**不可能**确定究竟那些数据是实际存在的)。所以,我们会观察到这样的行为:当我们创建了一个空文件,而后哪怕往里面只是写入了一个字节的数据,文件的**物理大小**却是4个KiB(即一个页的大小)——按照一个磁盘逻辑块512字节来算,那么就相当于是8个块的占用量。除了LunaixOS以外,这种现象在Linux下也可以被同样观察到的,如同下图中展示的一个演示:
777 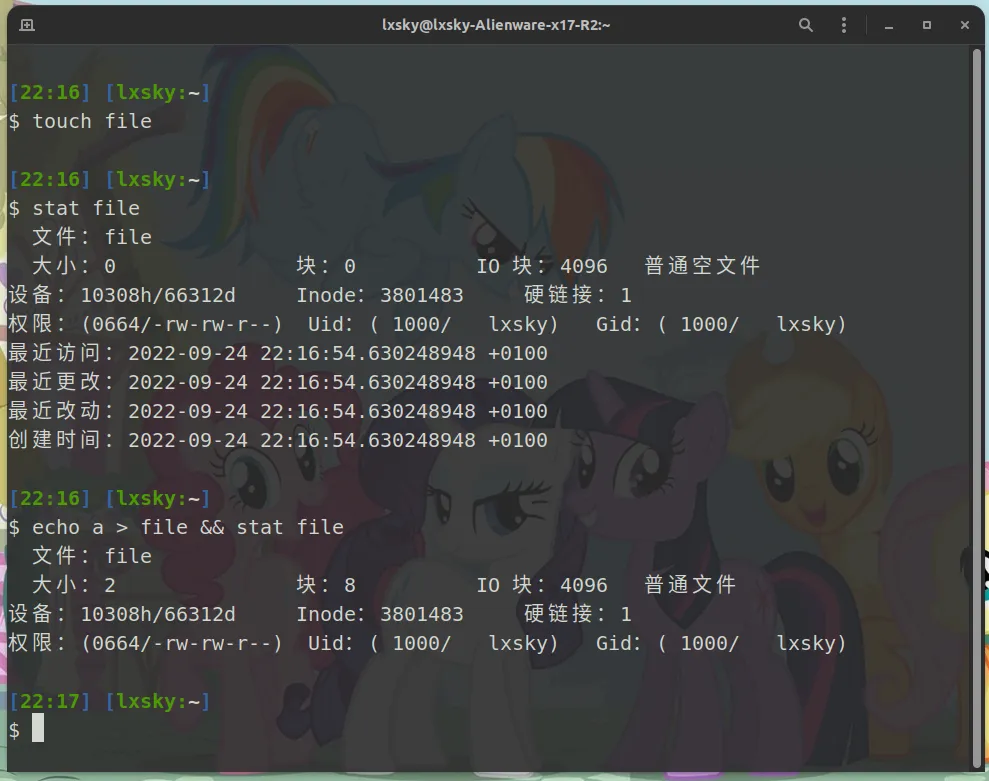
779 我们在这里首先用`touch`指令创建了一个空文件,和预期的一样,这个文件的大小和占用块都为零。之后我们往这个文件中随便写入了一个字符`a`,那么当我们再次查看时,我们就会发现占用块儿变成了8,但大小只有2(这是因为`echo`同时还会附加一个换行符,所以最后输入文件的是两个字符:`a`和`\n`)——这个大小是根据最后读取指针来计算的,所以这也就是为什么,我要在上面强调“物理大小”。那么在这里,读者其实也就不难猜到,我们总是讨论的页缓存,其实就是一直如雷贯耳的**IO块**。像上述的这种情况,据说也是应聘系统工程师时的一道经典面试题。
781 读者们可以在`kernel/fs/pcache.c`里面找到基于前缀树实现的页缓存机制的完整实现。实际代码非常的简单易懂,所以这里就不再放对应的伪代码了。
785 哦哦,我知道你在想什么,但先别激动!LunaixOS不会自动帮你清理电脑垃圾——这个不是标题的意思,那么也自然没有那个悬浮在桌面上的绿色小球了!
787 垃圾回收(Garbage Collection),想必学过java的同学应该对这玩意儿深有感悟,这东西的配置可谓是JVM调优时的黑魔法之一。垃圾回收的用处就是将一些没用的对象清理出去(这也许就是为什么我至今还单身的缘故吧~),这在我们的虚拟文件系统里面也是这样的。各位其实可以看到,我们到目前为止出现了用于抽象文件的`v_inode`,用于抽象目录结构的`v_dnode`,以及为了提高文件读写效率的页缓存机制。这些东西会随着每一次用户跟文件的交互,根据实际文件系统里的记录被创建出来,供用户使用。当用户使用完后,就被缓存在内存中,只为能够更加快速的响应用户下次的交互请求——听上去相当的美好,不过正如同俗话说:“计算机科学中最难的事情有两个,命名和缓存。”——缓存什么,何时缓存,何时释放——于是也就成了我们的在设计虚拟文件系统时的三大“哲学问题”了。
789 总结一下,我们目前已经回答了前两个的问题:
791 + **缓存什么?** 文件对象`v_inode`,和虚拟文件树节点`v_dnode`。
792 + **何时缓存?** 当用户访问到这个文件时(包括路径游走时路过的那些)。
795 最后一个问题是最难的部分,要回答这个问题,我们得要搞明白两点:1)如何评估一个缓存应该被释放;2)如何管理每一个已经创建的缓存。其中,后者是实现前者的先决条件。
797 在这里,对于前者,我们可以做一个对象池——非常简单,用一个链表将所有已经创建的同类型的对象串起来就好了;至于第二个问题,则有两种非常流行的选项——这些选项可以说是这类缓存问题的标准答案:LRU和LFU,他们分别是近期最少使用优先(Least Recently Used),和最不频繁使用优先(Least Frequently Used)。
799 从字面意思上理解,LRU释放的是最近一段时间**没怎么用过**的缓存。LFU释放的是**用的最少**的缓存。别看他们两个仅一字只差,但是其产生的效果确实千差万别。为了看到这一点的差距,我们首先来讨论一下LRU的实现。对于LRU的实现,我们可以采用一个栈来实现。当我们使用一个对象的时候,我们直接从栈中将他抽出来,用完后将他重新入栈。如果我们一致按照这种方式来编排队列中的元素的顺序,那些不收我们青睐的东西就会自然而然的沉积到栈底——就像是一缸子的鲶鱼似的,只有那些翻腾的最厉害的才能够浮上来,而那些沉默的就只能慢慢向下掉,最终被上面的压死。
801 但是这种有一个比较严重的问题,采用LRU策略的回收器容易出现短视主义的问题。考虑目前栈中的两个对象A和B,如果我们使用的顺序是BBBBBA,那么在最后一次的使用的时候,A就会被带到栈顶,而假若这时回收器刚好开始回收,自然而然的B就会被清理掉——哪怕这个A是唯一的一次访问,哪怕在这A之后全是B的访问。
803 为了解决LRU带来的短视主义的问题,人们才意识到需要考虑这个对象有史以来的使用频率,需要以史为鉴,于是就有了LFU的存在。那么在一般情况下,LFU的实现会以堆的形式(或者叫做优先队列)出现。可是这样还是存在一个非常明显的边界条件上的问题。同样我们假设队列中只有对象A和B.当一系列的,A十次,B十次的访问后,忽然有某个用户决定访问对象C,那么C就被带到队列中,频率计数器为`1`。那么,假若紧接着,回收器开始营业,根据LFU的策略,C是一个相当理想的释放对象——哪怕A和B是再也不会被访问,哪怕在这之后全是C的访问!
805 这就是LRU和LFU两种策略之间的差别以及一些短视主义上的问题。事实上,关于缓存何时释放的问题,一直是一个非常热门的研究方向,网上也有许许多多的讨论和教程。由于篇幅上的限制,我就不往下拓展了。尽管在我们文件系统中的这个例子里面,LFU是有着要比LRU更好的缓存利用率;不过出于实现的简单性的考虑,LunaixOS最终还是决定使用LRU作为主要的缓存释放策略。这其实也是有性能的优势:在LRU中,释放一个对象,和使用一个对象的时间复杂度均是 $O(1)$ ;相反,LFU——如果用堆去实现——这个时间复杂度就是 $O(\log_2 n)$ 了。
807 明确了缓存释放的策略后,我们还需要明确策略执行的时刻,毕竟我们可以看到,这也是和缓存的性能有着密切的关系。对于这个问题,同样,也是没有一个明确的答案,是取决于实际应用的场景。LunaixOS给出的答案相当的粗暴简单:缓存一切,及至内存爆满(不管是不是因为缓存引起),我们才开始执行释放策略。像这种方法也同样被Linux所采用的——所以这没什么好羞耻的!毕竟KISS原则能够正当化我们一切的“偷懒”行为。话归正题,这种“不见棺材不掉泪”的策略实现起来虽然简单,但也为我们带来了一个新的问题:“一次释放需要释放多少”——LunaixOS目前采用的是类似于半衰期的做法:每次释放一半的对象。虽然简陋,但就目前来说(而且在大部分时候)已经足够了。
809 那么我们下面来看看这个LRU策略的具体实现。
813 在LunaixOS里面,LRU缓存策略的实现有两个部分构成:第一部分是LRU节点,其实无非就是一个简单的链表节点,我们LRU的实现将会利用链表来进行,任何需要被缓存结构体都必须包含这个节点作为其成员字段;第二部分是缓存池,蕴含整个LRU链表,是所有缓存节点的集合。那么像这种缓存池除了能够为我们的所以已缓存的对象提供一个统一的管理以外;它的另一个用处就是对不同类型的缓存对象们提供一个上下文信息,同时进行聚合和分区:比如我们希望`v_inode`有`v_inode`的缓存,而`v_dnode`也有他自己的一块儿区域,而对于这两种不同的缓存类型,其缓存释放的条件也会不一样。那么这么一来,我们就可以实现更加细粒度的缓存管理。那么也正因为这一点,我们允许不同的缓存池之间相互链接,形成一个缓存池链表。而后允许统一管理。就如同下图所示的那样:
815 
817 所以我们也就能够写出缓存节点`lru_node`以及缓存池`lru_zone`的定义。首先我们来看看缓存节点的定义:
822 struct llist_header lru_nodes;
827 而这也就不难猜到我们使用一个缓存的对象时需要执行的操作了:
834 lru_use_one(struct lru_zone* zone, struct lru_node* node)
836 if (node->lru_nodes.next && node->lru_nodes.prev) {
837 llist_delete(&node->lru_nodes);
840 llist_prepend(&zone->lead_node, &node->lru_nodes);
845 我们可以看到,释放一个对象(以及缓存一个对象)都需要以缓存池的引用,其定义如下:
850 struct llist_header lead_node;
851 struct llist_header zones;
853 int (*try_evict)(struct lru_node* lru_obj);
859 + `lead_node` LRU链表的领头节点。
861 + `objects` 缓存池中对象的数量
862 + `try_evict` 对象释放前的检查和回调函数,回收器会在释放一个对象之前使用该函数进行检查可释放性。如果说这个对象可以释放,那么这个函数还必须要执行相应的解构动作。
864 ### LRU策略实现的VFS垃圾回收机制
866 截至目前,我们已经完成了对LRU策略的实现,接下来要做的就是接入我们的虚拟文件系统的实现。那么我们完事儿了吗?当然没有——难道一切对象都是可以被释放的吗?毕竟我们不可能因为一个文件对象太长时间没访问过就无脑的进行释放,而不管是否有任何现有的程序在使用它。所以这也就是为什么,在`v_inode`和`v_dnode`的结构体定义中,会有一些计数器字段:`v_dnode::ref_count`以及`v_inode`里面的`open_count`和`link_count`。
868 为什么`v_inode`会需要两个计数器去实现相同的功能?读者也许会这么问。`open_count`——这个就是字面意思了,用于跟踪该已经打开,并且正在使用该文件的使用者数目。至于`link_count`现在来说还为时过早,我们会在涵盖文件的软硬链接时说道。总而言之,一个`v_dnode`或`v_inode`可以被释放需要满足这几点的条件:
870 + `v_dnode::ref_count == 0` 确保没有程序占用该路径节点(比如进程的工作目录)
871 + `v_inode::open_count == 0` 确保没有程序正在使用该文件
872 + `v_inode::link_count == 0` 确保当前的文件对象没有任何的引用(换句话讲,就是没有被任何路径节点引用)。
874 这也就是我们什么,我们需要在`lru_zone`里面添加这个`try_evict`的回调与检查函数。在我们的这个例子中,我们需要两个`try_evict`函数,分别对应这两个类型的节点:
878 __vfs_try_evict_dnode(struct lru_node* obj)
880 struct v_dnode* dnode = container_of(obj, struct v_dnode, lru);
882 if (!dnode->ref_count) {
890 __vfs_try_evict_inode(struct lru_node* obj)
892 struct v_inode* inode = container_of(obj, struct v_inode, lru);
894 if (!inode->link_count && !inode->open_count) {
902 到这里,一个很自然的问题自然会浮现在我们的心中。我们可以看到,对与`v_inode`的解构处理非常简单,就直接释放分配给`v_inode`的内存就好了,当然了,我们也需要去通知底层的CFS在进行额外的解构操作,毕竟我们还有一个专供CFS使用的`v_inode::data`。而对于路径节点`v_dnode`的解构操作就没有那么显而易见了。
904 为了看到这一点,我们可以假设一个路径节点A满足释放条件,也即将被释放。但是A并非是一个单纯的子叶节点,换句话将,A是其他路径节点的父节点。显然,我们不能够就地的去遍历整个子树,然后逐个的释放,因为这相当的低效。在这里,我们给出的解决方案是直接释放节点A(同时将A从他的兄弟节点的链表中移去),而后对A原有的每个子节点,将他们对A的引用清除掉,也就是`v_dnode::parent=NULL`。这样,我们就会产生多个孤立子树。而这正是我们想要的,这种孤立的子树将不会在之后的路径游走过程中访问到,久而久之,这些子树节点便会沉降到LRU链表的最末端,从而在下次释放周期时被清理掉。如此往复,这种操作会递归的进行,及至这个子树的最后一个节点被释放。
908 vfs_d_free(struct v_dnode* dnode)
910 assert(dnode->ref_count == 1);
913 assert(dnode->inode->link_count > 0);
914 dnode->inode->link_count--;
917 vfs_dcache_remove(dnode);
918 struct v_dnode *pos, *n;
919 llist_for_each(pos, n, &dnode->children, siblings)
921 vfs_dcache_remove(pos);
924 vfree(dnode->name.value);
925 cake_release(dnode_pile, dnode);
931 一切的缓存都可以通过LRU去策略管理(毕竟他就是用来干这个的),这对于页缓存来说也是如此。我们将所有的存在的缓存页——不论其归属的文件——统统塞进我们的LRU队列里,等到内存空间爆满的时候再按照先前讲述的“半衰期释放法”,释放掉一半就好了。
933 显然,直接释放不是一个好的做法,因为一个程序有可能对某个缓存页进行了数据的修改——缓存“脏”了。对于这种的情况,我们就需要在释放前执行一个数据 **回写(Write-Back)** 的操作。当然,除了回写的办法,我们其实也可以在用户执行第一次写入的时候就将这个写入操作同时进行落盘操作——对于这种方式我们一般叫做 **透写(Write-Through)**。究竟用哪一种方式?这和缓存管理的所有问题一样没有一个客观绝对的回答,而都是需要我们具体情况具体分析。从一般来看,回写和透写会在以下三个应用场景有着对性能不同的影响:
936 读取的频率远高于写入的频率。显而易见,那么这种情况下,回写和透写的区别也就没有什么特别的明显了。
938 写入的频率远高于读取的频率。这种就一般会建议采用回写的方式——我们可以将多次的写入整合进一次IO写操作。但这样以来,我们就必须要决定一个合适的回写时间点——于是又回到了我们“缓存哲学三大问”的最后一问上了。
940 这其实是一种最复杂的情况。在这种情境下,一个数据源内容一致性是非常重要的。一个最有名的例子的就是CPU里面对内存访问的缓存机制。不同的CPU核心由他自己的缓存(L1,L2),那么这也就存在同一个内存地址有着多种不同缓存的可能性。对于这种情况,使用透写策略似乎是一个非常好的解决方案。任何核心对其该内存地址的缓存数据做出更变,都会立刻下发到下级的L3缓存,或者是直通内存。但是这样一来又会存在可能的由高频写入场景带来的性能上的牺牲。这些都需要芯片设计者进行分析与权衡。
942 由于在LunaixOS的设计中,页缓存是在`v_inode`层面的,任何对该`v_inode`的并发访问都是共享同一个页缓存,因此不会造成任何缓存一致性上的问题。所以上述的第三个应用场景也就不在我们的考虑范围。那么剩下的问题就是在于透写与回写之间的选择。从理想的角度来看,这两种方案都须由操作系统支持,而将选择权交由上层应用程序,因为只有他们才知道具体的应用场景。这也就是为什么,在Linux下,`open(2)`系统调用会存在一个`O_DSYNC`的选项(如果希望同时对文件元数据的更新应用透写策略,那么就需要使用`O_SYNC`),这个就对应着透写策略。但是在目前的阶段,出于简单性的考虑,LunaixOS只提供回写的支持。
944 同样,读者可以在`kernel/fs/pcache.c`下面找到页缓存同步和释放的实现。
948 LunaixOS所处在的是一个并发的环境。假若我们在后日实现了多核心的能力,那么这将会是一个并发且并行的环境。在这种混乱无序的环境里,虚拟文件系统作为一个由所有进程共同享有的组件,自然要做到自己的洁身自好和出淤泥而不染。而做到这一点的关键,就是去设计出一套同步的办法,让所有无序的并发访问变得有序。
953 > 这应该是一个相当显然的问题,我相信各位读者或许都通过不同的渠道有所了解。简单来讲,上锁的目的就是保证在并发访问一个共享的对象时,各个进程(或线程)访问到的内容都是一致的,并且是完整的——这是非常重要的,因为那会直接影响到程序运行的正确性。
955 > 我们可以举一个简单的例子。考虑对文件的并发写入。假设有两个进程,A和B。其中,B是A的子进程,因为`fork(2)`的缘故,B将会继承所有已被A打开的文件实例(关于这一点,读者可参考`kernel/process/process.c::__copy_fdtable`)。那么,A和B在使用一样的文件描述符去访问一个文件时,那么这个就是引用的就是同一个`v_file`实例,显然也是同一个`v_inode`。如果他们都希望对一个文件进行写入操作,那么理想的顺序应该是这样的:
962 > 但是当他们同时进行写入操作时,这几个动作会随着我们运气的好坏,在满足操作依赖性的前提下,以不同的时间顺序发生。这也就是说,“在读写指针处写入数据”的操作总是在“更新读写指针的”的操作开始之前——这是一个必须满足的操作依赖性。但是时间顺序——究竟是A先进行还是B先进行——就是一个纯粹的运气问题。比如,顺序1,3,2,4或者1,3,4,2都由可能发生(但不可能是2,1,3,4或4,2,3,1)。那么这样一来,除了第一个进程写入的数据会被第二个进程覆盖,读写指针的不正当更新也会在后续对该文件一系列读写操作带来不好的影响。
964 > 这种情况就是由 **指令交织 (Interleaving)** 导致的 **竞态条件 (Race Condition)** 。所以,我们必须要有一种机制,去保证A在结束他的一系列操作前,B不能够“瞎掺和”。这个机制就是同步机制,或者也叫做锁机制。
967 这是一个相当复杂的问题,因为首先我们需要明确VFS中的那些对象是需要同步的,并且识别出任何的**关键代码区 (Critical Region)**——也就是任何容易受并发访问影响的区域,以设计与施加我们的同步机制。在目前VFS的实现中,几乎所有的对象都有被并发访问的可能性,下面我们就会对每一种对象进行分析和论证:
970 文件节点的并发访问是很显然的。因为只要有文件的操作,自然就有访问`v_inode`的必要。
972 目录节点作为链接`v_inode`和虚拟文件树的桥梁,其定义的是虚拟文件树的拓扑结构。那么自然地,任何有可能修改文件树结构的操作都需要进行同步。
974 这个作为访问虚拟的inode的入口点,维护着操作文件所需要的一些信息——比如读写指针。因为任何对这些信息修改的行为必然伴随着对`v_inode`的使用,所以,`v_inode`自身的同步性也就可以作用于`v_file`上。故此处无须额外的同步机制。
976 和`v_file`同理,任何对页缓存的操作都会伴随着对`v_inode`操作。此处也无须额外的同步机制。
978 这个情况和`v_dnode`非常相似。因为两者都是用于维护某种树结构。故该对象需要同步机制。
980 接下来就是对同步机制的设计以及关键代码区的辨认。因为`v_mount`的同步机制是可以由`v_dnode`的机制推导而出,故下文主要讨论`v_inode`和`v_dnode`的同步机制的设计。
984 对于此类节点的同步的机制,一个显然的设计就是在每次执行任何的文件操作之前,就将该`v_inode`锁住;而后在操作结束后释放锁。同时,我们也可以注意到,我们的每一次的上锁其实都是对`v_inode`的一次引用。而这也是为什么,在LunaixOS中,上锁的操作,和刷新该对象在LRU队列中的优先性的操作是同时进行的。为此,这两个操作可以被整合进同一个宏中:
987 ##define lock_inode(inode) \
989 mutex_lock(&inode->lock); \
990 lru_use_one(inode_lru, &inode->lru); \
994 但是上述的设计有一个非常严重的问题,那就是存在死锁的风险。为了演示这一点,考虑两个进程,A和B。这两个进程——不论是否存为父子还是相互独立——都打开了同一个文件,于是也就引用了一个同样的inode。这时,我们假设A希望对这个文件进行读取操作,B希望进行写入操作。并且——也许是B的上辈子烧了高香——他比A先抢到了执行操作的机会,那么A就因为锁已被占用,而不得不进行等待。如果说进程B在写入的过程中忽然的被终止了——有可能是用户的决定,也有可能是写入的过程中发生了什么错误,比如B向操作系统提供的数据缓存区触发了SEGV信号。而这个时候,问题就产生了:因为B在释放锁之前就被强行终止了,这就会导致A将会一直等待永不会释放的锁——从而导致任何尝试访问这个文件的进程进入死锁状态。
996 解决这个问题其实也不难,相比各位也都看到了,这无非就是在调度器销毁进程的时候,增加一个对`v_inode`锁的释放就好了。但我们不能盲目的释放,因为这会引发另一个问题:同样,我们假设进程A和B的存在,并且打开的是同一个文件。A正在进行很耗时间的写入,而B却没有对这个文件做任何事情。B比A提前退出,根据设计,B会在销毁阶段直接释放被A锁住的锁,从而导致A的操作在B之后出现被干扰的可能。
998 而这也就意味着解铃还须系铃人——我们需要在释放锁前,进行一个所有者的检查。该检查将会有另一个专门的函数来进行:`mutex_unlock_for(mutex_t*, pid_t)`
1001 if (mutex_on_hold(&file->inode->lock)) {
1002 mutex_unlock_for(&file->inode->lock, pid);
1006 最终的实现也就能够保证整个同步机制的正确性了。
1010 目录节点的同步机制要比上述的文件节点复杂一些。这主要是因为其关键代码区并不是特别的明显——他不像是文件节点那样,我们知道任何设计文件操作的区域是敏感的。
1012 从总体上讲,目录节点的同步机制主要是为了保证虚拟文件树结构在并发访问情况下的一致性。考虑一个简单的场景,同样的,我们有两个名称为A和B的进程。其中,A希望对一个空目录D进行重命名操作——这个操作有可能会导致目录的移动;B希望对同一个目录进行删除操作。在这个过程中,涉及到对文件树结构的访问总共有两次:路径游走以定位操作对象,以及因为目录操作而导致的文件树结构的更改。
1014 其中,我们可以发现,文件树结构的一致性必须要在路径游走的过程中得到保证——我们不希望B在A移动目录D的过程中去尝试锁定D,因为这很有可能B会锁定D的一种中间状态,比如A已经切断了父节点的连接,但还未来得及与新的父节点建立连接。而这就要求我们在游走的过程中,每到一个地方就上一个锁,向其他可能的访问宣布我们的在这里的主权,而后在离开的时候进行解锁。但是这在LunaixOS目前的实现中其实并不是必须的,因为在单核模式下,当通过系统调用进入内核层时,调度器此时就只能被手动触发——这是一个相对可控的,且CPU独占的环境,所以也就没有其他进程的干扰之忧。不过我们还是在实际的代码中实现了这种加解锁模式,未雨绸缪地为之后可能实现的多核心支持做好准备。
1017 def lookup(start_dnode, path):
1018 (filename '/' subpath) = path # 模式匹配
1021 start_dnode = root_node
1025 if filename in start_dnode.children:
1026 dnode = start_dnode.children[filename]
1028 dnode = new v_dnode(name=filename)
1029 start_dnode.inode.lookup_file(dnode)
1031 start_dnode.children.add(dnode)
1033 if dnode is symlink:
1034 + unlock(start_dnode)
1035 if depth excess the limit:
1037 link = dnode.read_symlink()
1038 dnode = lookup(start_dnode, link)
1041 start_dnode[filename] = dnode
1043 + unlock(start_dnode)
1044 if subpath is empty:
1047 return lookup(dnode, subpath)
1050 在上面的加了锁的路径游走代码中,需要注意的一个细节就是我们在递归进行符号链接解析之前,对`start_dnode`进行解锁,而后在上锁——这可不是脱了裤子放屁,而是为了防止死锁问题的产生。关于这点,我们其实可以很容易的看到,如果我们解析的符号链接是一个相对路径,或者是一个和当前所在目录的路径有重合的绝对路径。那么就产生了死锁,这是因为在对符号链接进行递归游走时的加锁操作,会使得它去等待一个只有这个递归结束时才会释放的锁。
1052 
1054 另一个解决的问题就是如何确保在执行目录相关的操作时,保证被操作目录自身以及其周围结构的一致性。为了做到这一点,我们就需要明确一个改动发生时,有些那些结构会受到影响,而后在具体的操作时锁定这个结构——对于这些结构在这里为他们赋予一个新的名称:临近结构。这是一个和操作相关的定义,不同的操作,临近结构的范围也不一样。我们将会逐个讨论:
1058 对于这一类的操作,会发生改变的结构是被删除目录的上级节点的子树结构。所以,在这里,我们除了锁定被删除目录外,还需锁定这个上级节点,
1061 和目录的删除操作一样,其临近结构是目录创建地的子树结构,我们这里只需要锁定这个目录,以确保在添加新目录节点的时候,不会有别的操作来和我们竞争。
1064 这种情况就稍微有点复杂了。首先我们可以确定的是,其临近结构必定包含被重命名的节点和其上级节点。由于一个重命名可能涉及到子树的重定位(情况一),被重命名目录的目标父节点也就需要被锁定;另一种情况(情况二)就是,如果被重命名目录的新名称是另一个已存在的文件夹的名称(该文件加必须为空),那重命名的操作其实是进行一个替换,这就意味着除了我们上述的三种需要锁定的对象外,我们还需要锁定这个目录节点。所以,按照上述的两种情况,其临近结构会包含三个或四个节点。
1066 
1069 不会对任何的结构发生改变,是一个只读的操作,临近结构为空。
1071 上述就是关于目录节点的同步策略。和我们之前说过的一样,以LunaixOS目前的状态来看,目录结构是不会存在并发访问的忧虑。所以,这里所讨论的就只是为未来可能的多核心支持的一个准备。
1075 或许有读者已经发现了,我们所采用的同步机制都是基于十分的简单的互斥锁进行的。这种锁只能一次允许一个使用者——这也是我们想要的。但是,这样以来会导致相当低的吞吐量——于是也就是相当低的性能。一个显然的例子就是两个**独立的**进程对一个**非共享操作上下文的**文件的并发读取。因为他们是读的操作,自然不会影响到文件的内容,所以,不论有没有锁,一致性都可以在这里被保证。但是,因为互斥锁的使用,导致原本可以同时进行的操作,非要去排着队的,一个一个的进行。
1078 > **为什么强调进程的独立性和操作上下文的非共享性?**
1080 > 因为只有这样,我们后面的讨论才变得有意义。这是因为,假若两个进程是父子关系的,并且子进程是和父进程对文件的访问,是共享一个文件操作上下文环境,即`v_file`对象(这也意味着当在`fork(2)`时,父进程已经打开了后面父子进程即将操作的文件)。而这样一来,同步机制就必须要得到使用,从而保证读写指针的(或者一些其他和操作上下文环境有关系的信息)一致性,所以这也会作废我们上述的讨论。
1083 像这种情况的例子还有很多,比如我们对目录节点在路径游走时的锁定——如果我们仅仅只是为了确保目录节点的子树拓扑结构的一致性,那我们也没有必要去等待别的游走结束。
1085 这也就是为什么,我们会有一种叫做“读写锁”的东西存在。这种锁是有两个小锁构成的:读取锁和写入锁。其中,读取锁是可以被无限次获取的(根据应用场景的需要,也可以设置上限)。但一个写入锁只能同一时间被获取一次,并且在被获取前,需要等待所有的读取锁被释放。同样,读取锁只能在写入锁空闲时才可被获取。
1087 这种锁虽然能够提高我们的效率,但也会带来实现上的挑战。一个最明显的例子就是锁所有权的检查和释放——这个是我们用来解决`v_inode`死锁问题的关键。由于在读写锁中,进程和读取锁的关系并非是一对一的,如果我们使用简单的计数器来记录读取锁被打开的数量,那么这会使得我们失去读取锁的所有拥有者的信息,于是就会导致可能的“过释放”问题,使得计数器在某个时候溢出。一个可能的解决方案就是维护一个所有拥有者的查询表,但这样一来又会增加锁空间复杂度,和代码上的复杂度。这也是一个非常经典的时间空间复杂度权衡的例子。
1089 另一种更加高效和高级的方法就是使用 **RCU (Read-Copy-Update)** 同步机制,这也是Linux内核里面最常用的。他是一种和读写锁非常类似的同步机制,但不同的是,任何对采用RCU机制的共享对象的更新,必须要在该对象的一个副本上进行,然后通过修改对原始对象的指针引用来应用更新——这就能够允许整个更新操作在一次原子操作中完成;而不是像大部分采用锁的同步机制那样原地的更新,其更新操作为非原子的。这也就是为什么,采用RCU机制能够将同步所需的时间最小化——甚至在某些情况下做到类似于“无同步”的效果。关于RCU理论和应用方面的讲解,这里就点到为止了,因为这算是后期优化的任务。
1091 所以,由于简单的性的考虑,LunaixOS目前使用的是最基础的互斥锁实现。
1095 虚拟文件系统的设计不是一个简单的事情。可以看到,本篇文章洋洋洒洒的三万多字依然没有将所有的细节都给涵盖到。但不管怎样,涵盖所有细节也不是这篇文章的初衷——因为那是源代码的责任。笔者写本篇文章的本意主要就是向大家展示VFS的一个大致的原理和结构,以及每个组件背后的理论和一些需要注意的地方。希望能够为读者理解LunaixOS虚拟文件系统源代码提供有用的帮助。